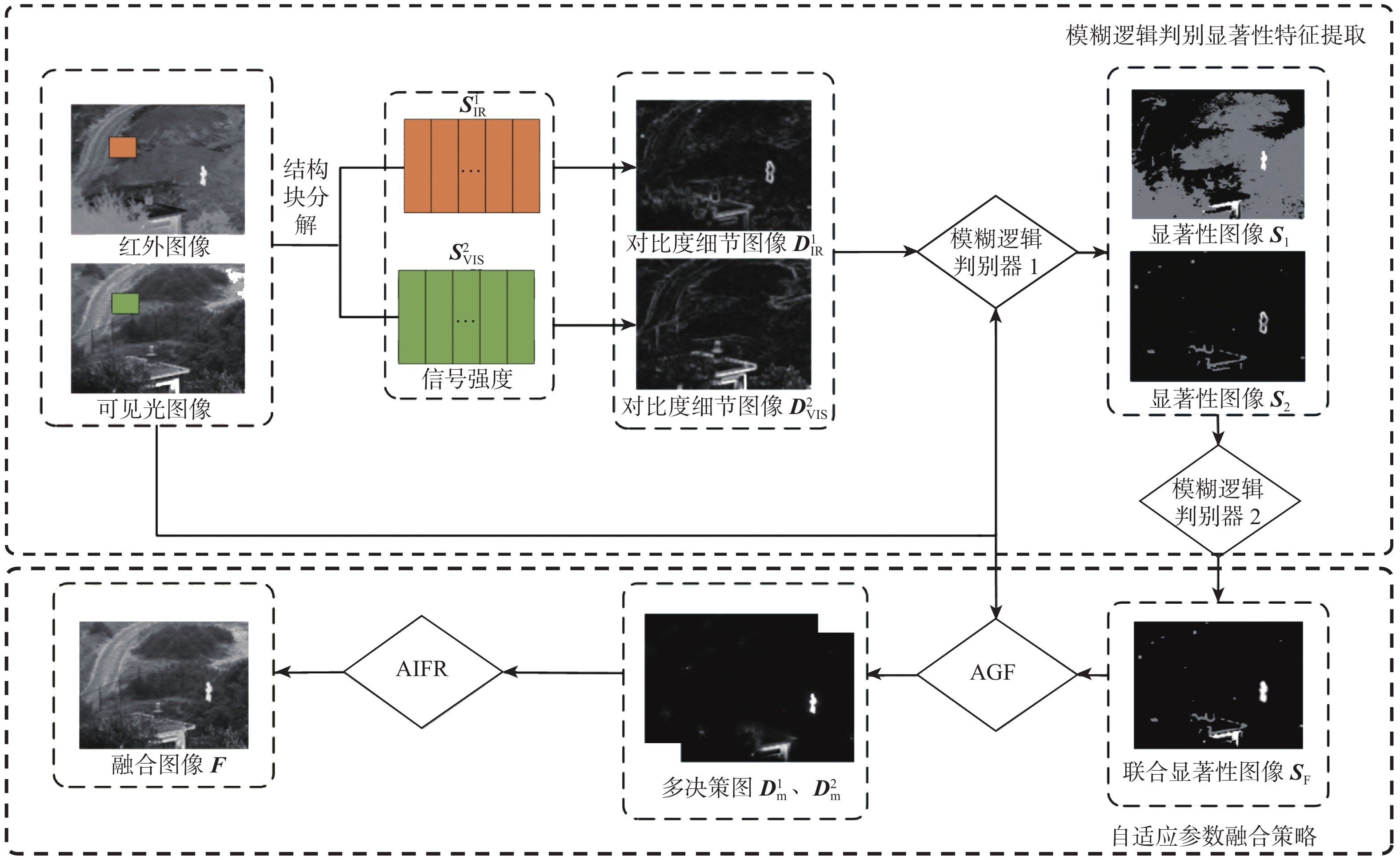
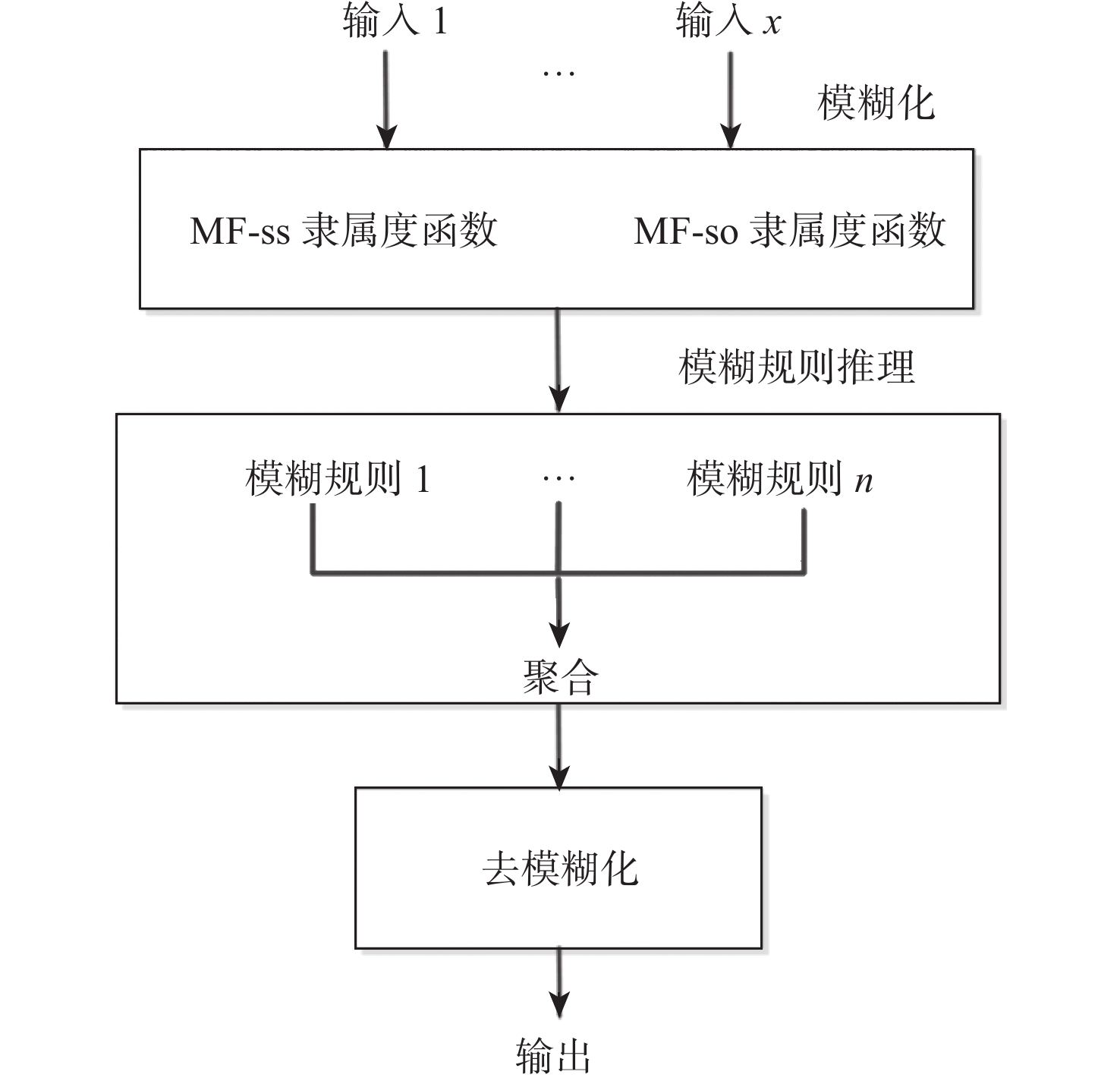
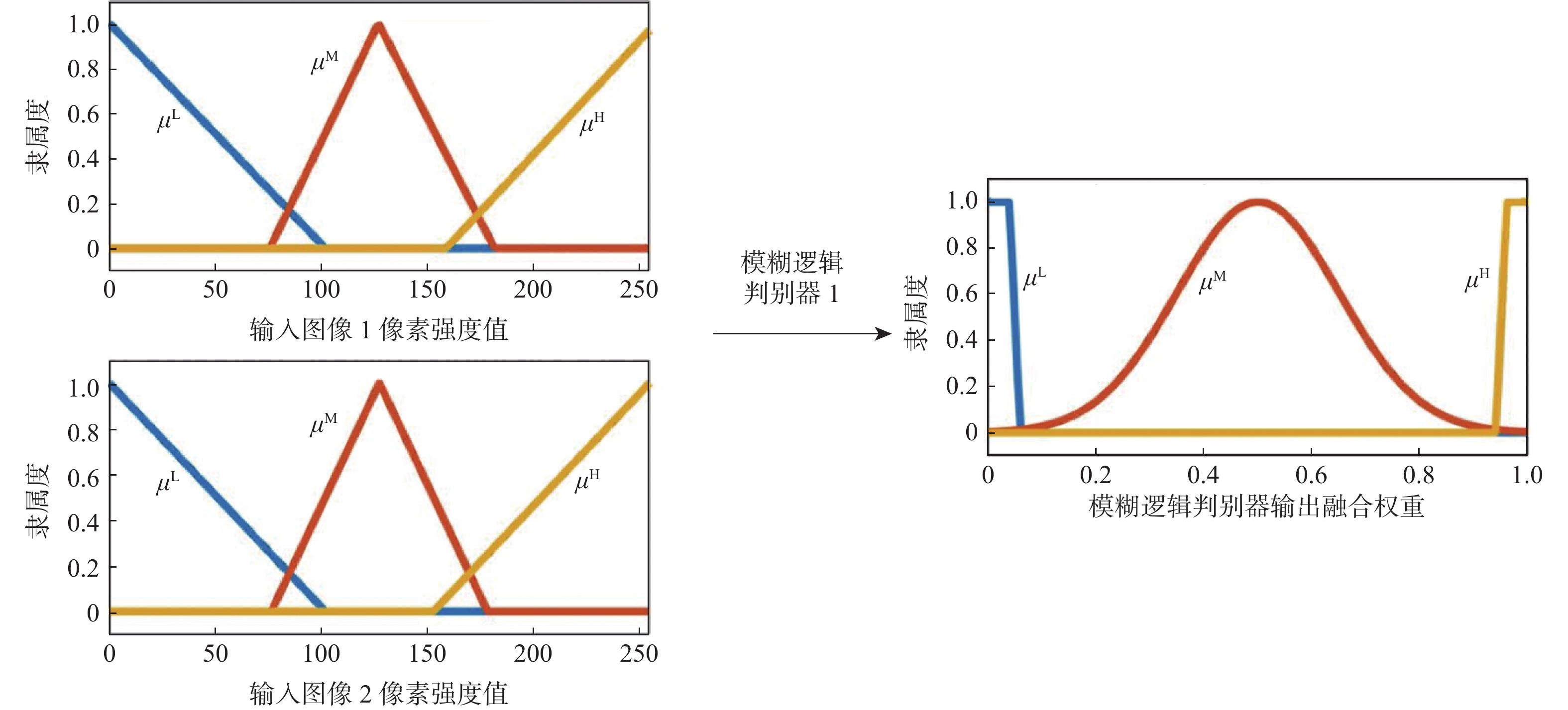
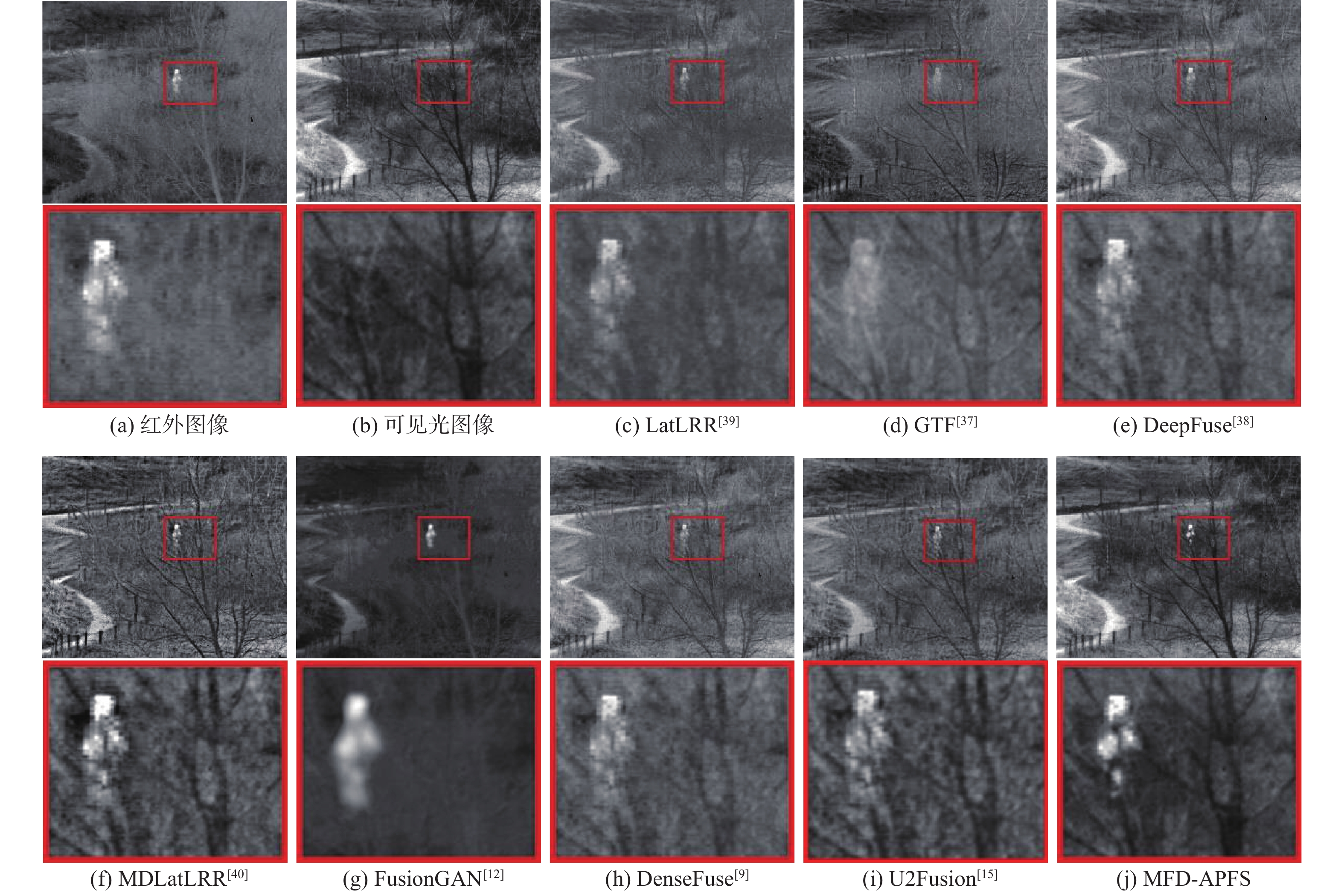
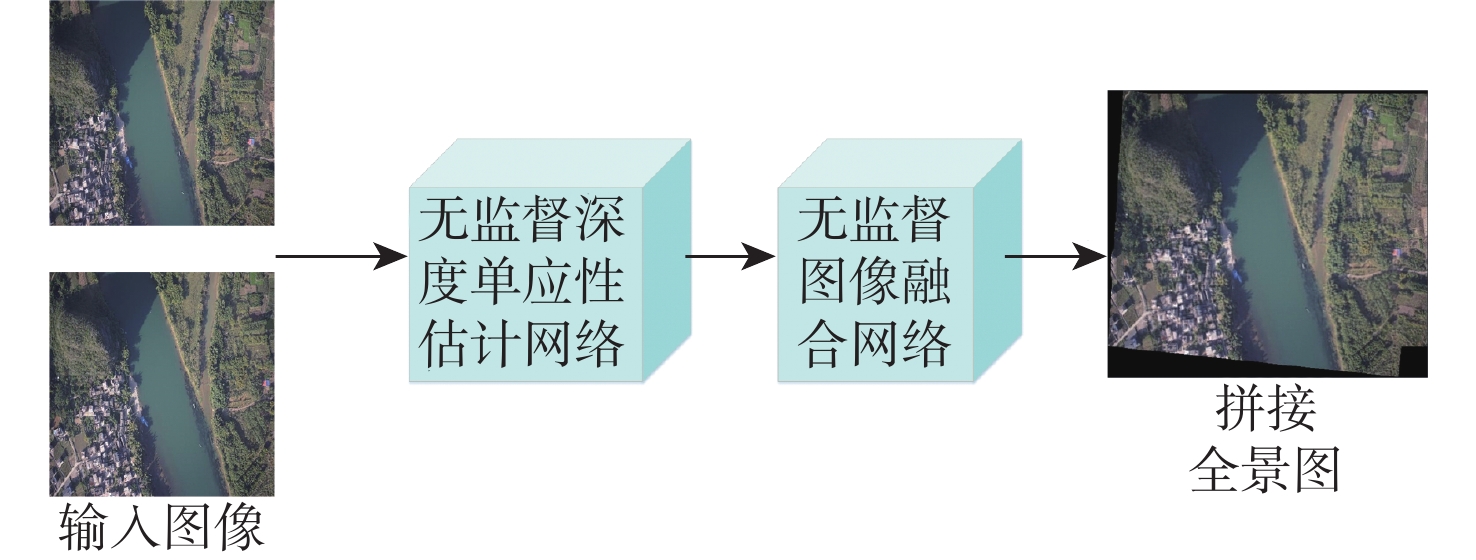
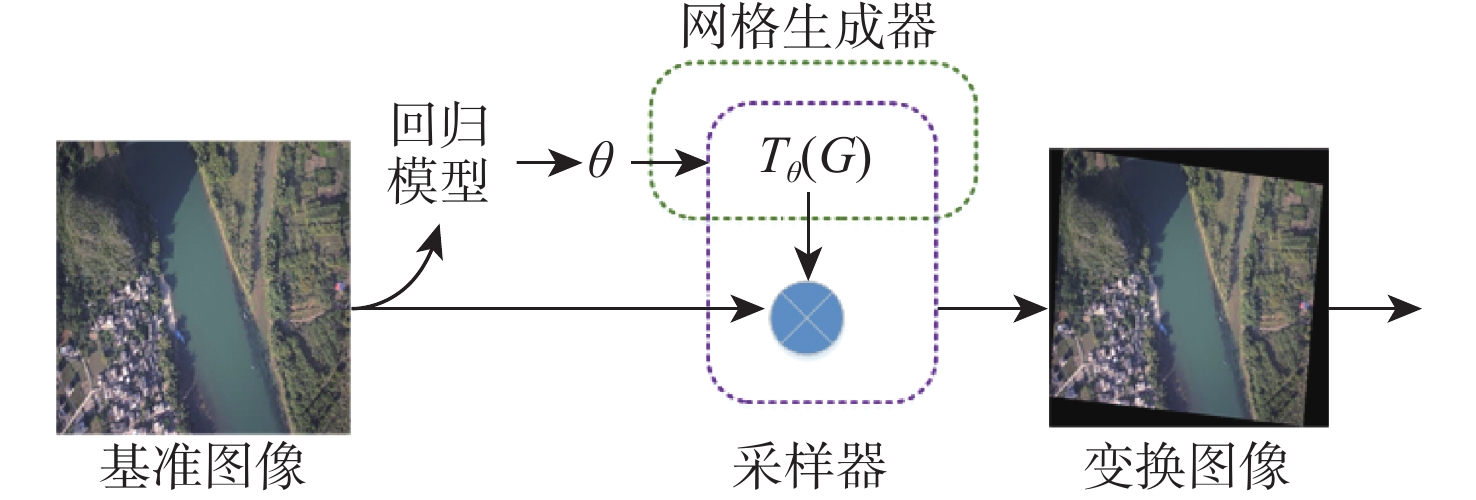
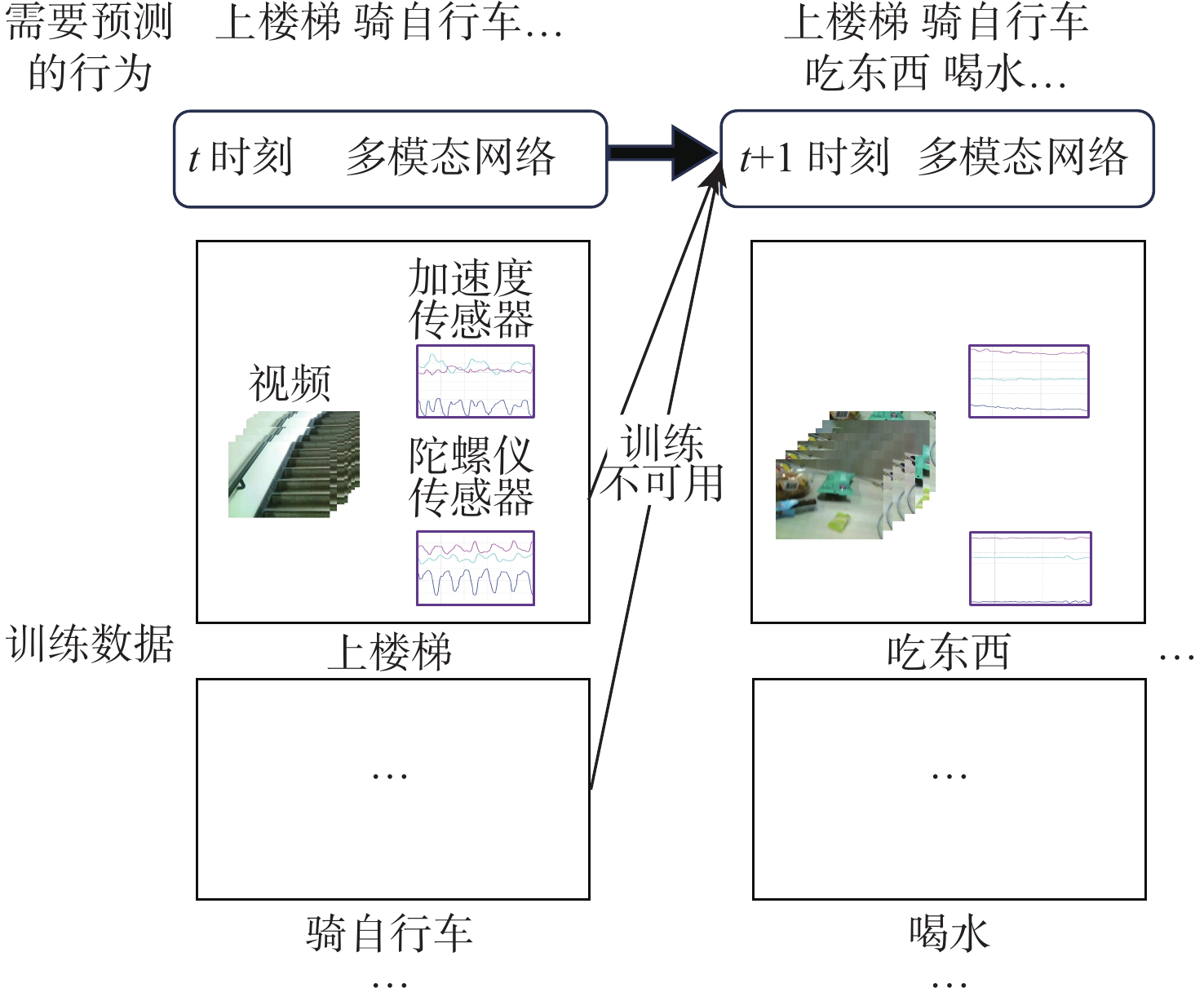
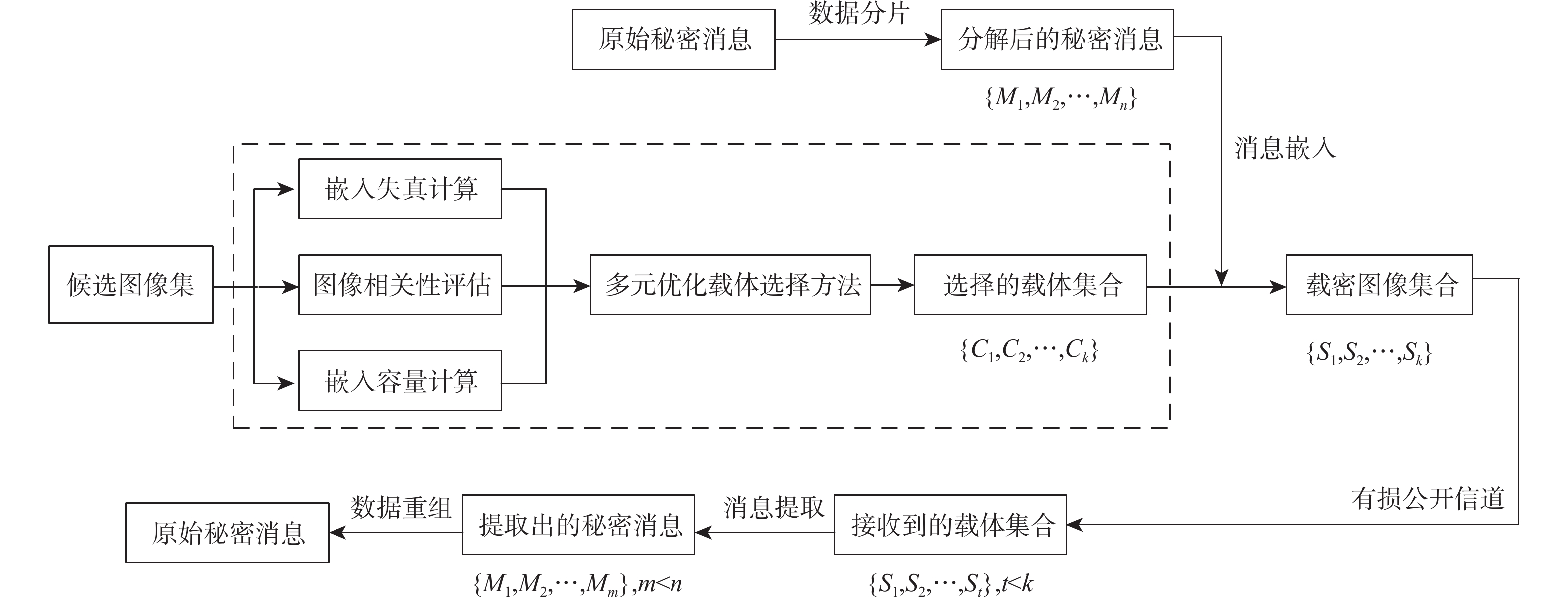
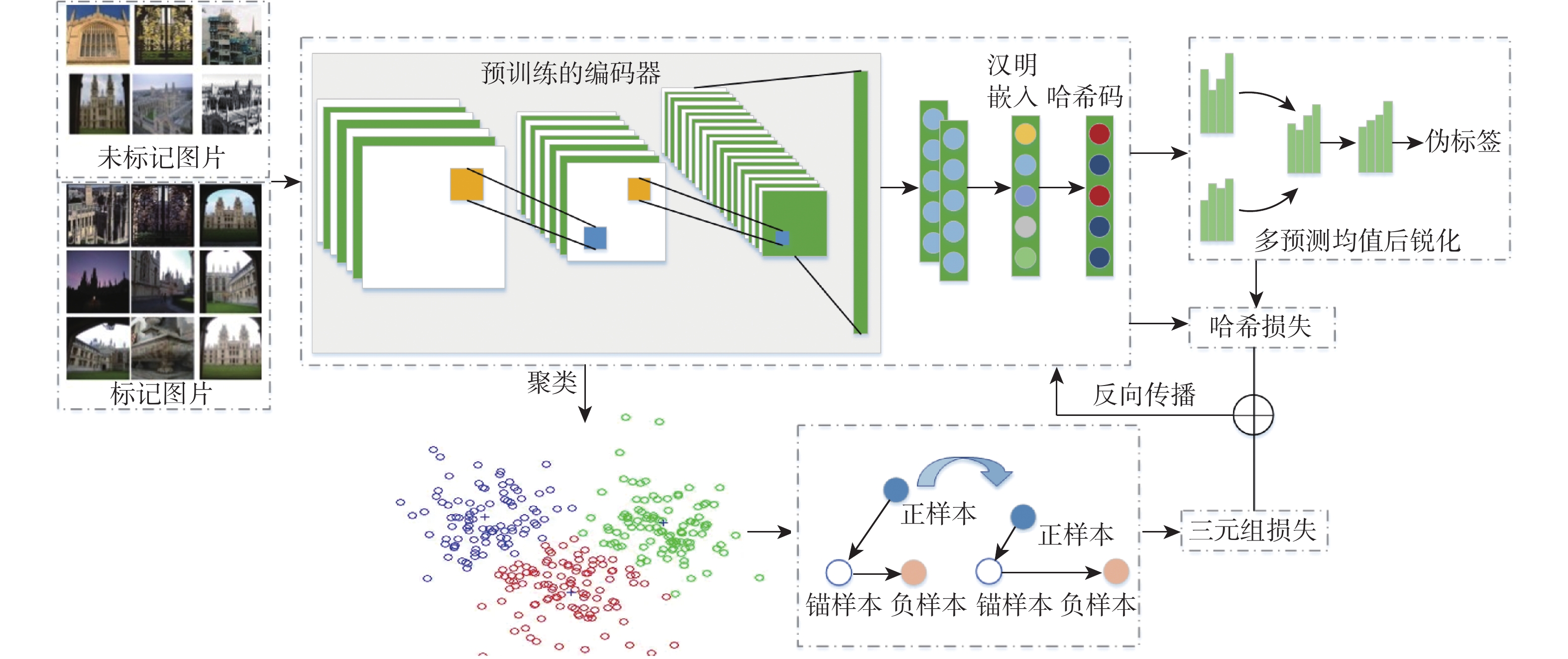
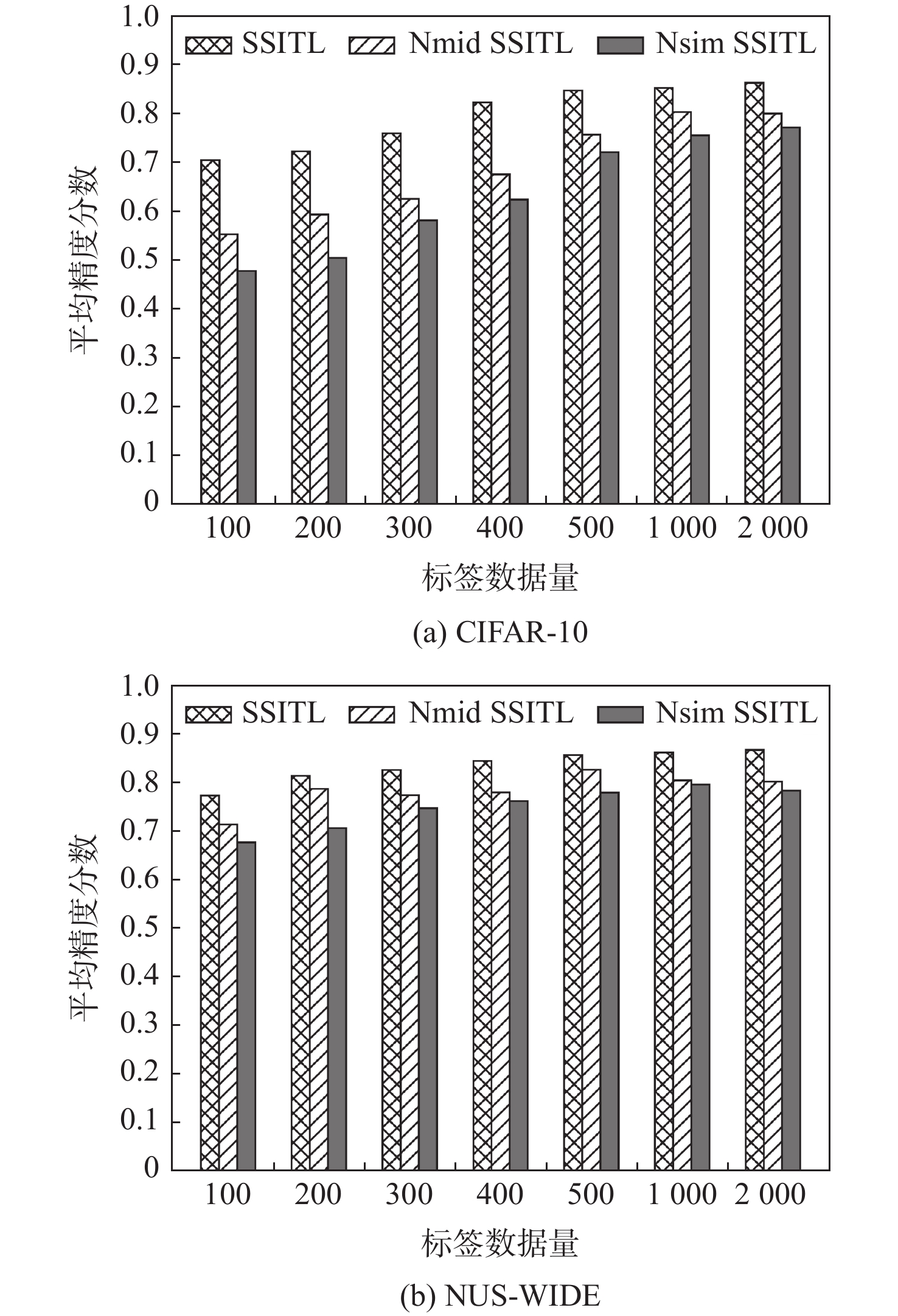
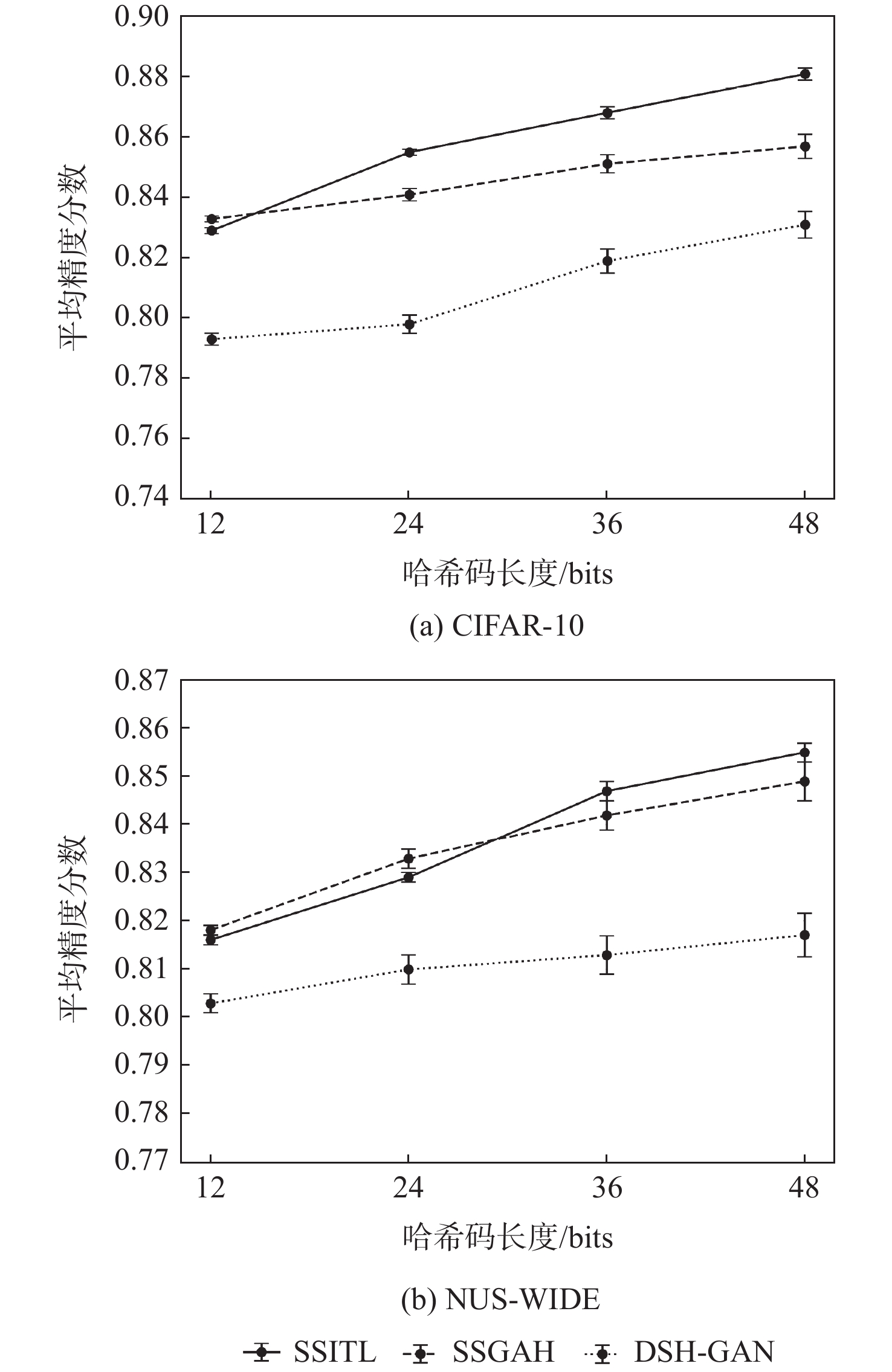
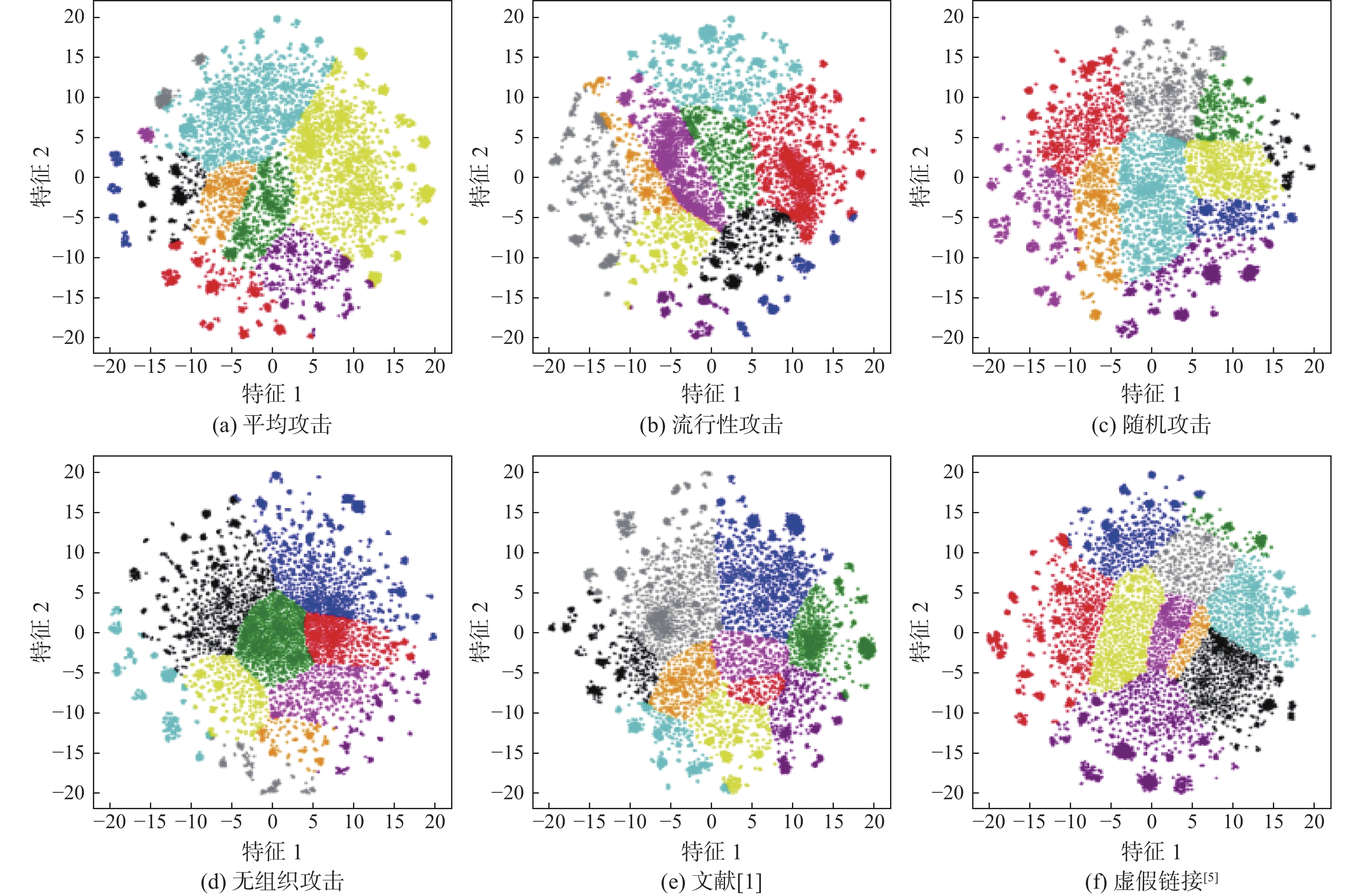
This paper presents a few-shot object detection of aerial images based on language guidance vision in response to the problem of decreased detection accuracy in existing aerial image object detection brought on by a lack of training data and changes in the aerial image dataset, such as changes in shooting angle, image quality, lighting conditions, background environment, and significant changes in object appearance and the addition of new object categories. First, a word-region alignment branch replaces the classification branch in conventional object detection networks, and a word-region alignment classification score with both language and visual information is obtained as a prediction classification result. Then, object detection and phrase grounding are unified into a single task, leveraging language information to enhance visual detection accuracy. Furthermore, to address the challenge of accuracy fluctuations caused by changes in textual prompts during few-shot object detection, a language visual bias network is designed to mine the association between language features and visual features. This network aims to improve the alignment between language and vision, mitigate accuracy fluctuations, and further enhance the accuracy of few-shot detection. Extensive experimental results on UAVDT, Visdrone, AeriaDrone, VEDAI, and CARPK_PUCPR demonstrate the superior performance of the proposed method. Particularly, on the UAVDT dataset, the method achieves an impressive mAP of 14.6% at 30-shot. Compared with aerial image detection algorithms clustered detection (ClusDet), density map guided object detection network (DMNet), global-local self-adaptive network (GLSAN) and coarse-grained density map network (CDMNet), the detection accuracy is 0.9%, −0.1%, −2.4% and −2.2% higher during full data training. The mAP of the approach can achieve 58.0% on the PUCPR dataset at 30-shot, which is 1.0%, 0.8%, 0.1% and 0.3% higher than the accuracy of full data trained generic object detection methods fully convolutional one-stage object detector (FCOS), adaptive training sample selection (ATSS), generalized focal loss V2 (GFLV2) and VarifocalNet (VFNET), respectively. These results highlight the robust few-shot generalization and transfer capabilities of the proposed method.




 Download (96974)
Download (96974) 
 Views
Views  Cited by
Cited by 
























































































































































































































































 XML Online Production Platform
XML Online Production Platform
