| Citation: | SUN G D,XIONG C Y,LIU J J,et al. Spatial information-enhanced indoor multi-task RGB-D scene understanding[J]. Journal of Beijing University of Aeronautics and Astronautics,2025,51(7):2209-2217 (in Chinese) doi: 10.13700/j.bh.1001-5965.2023.0391

|
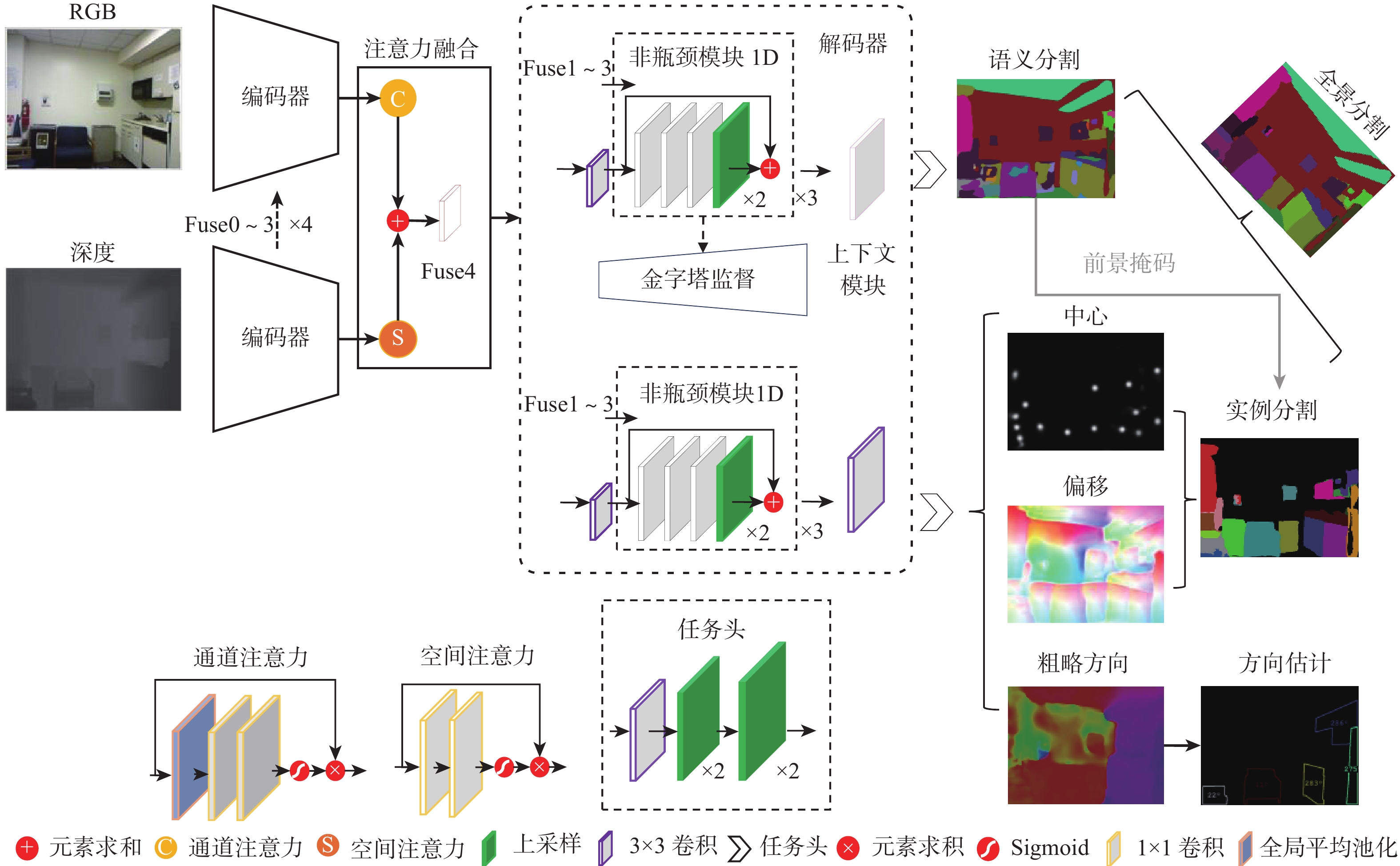
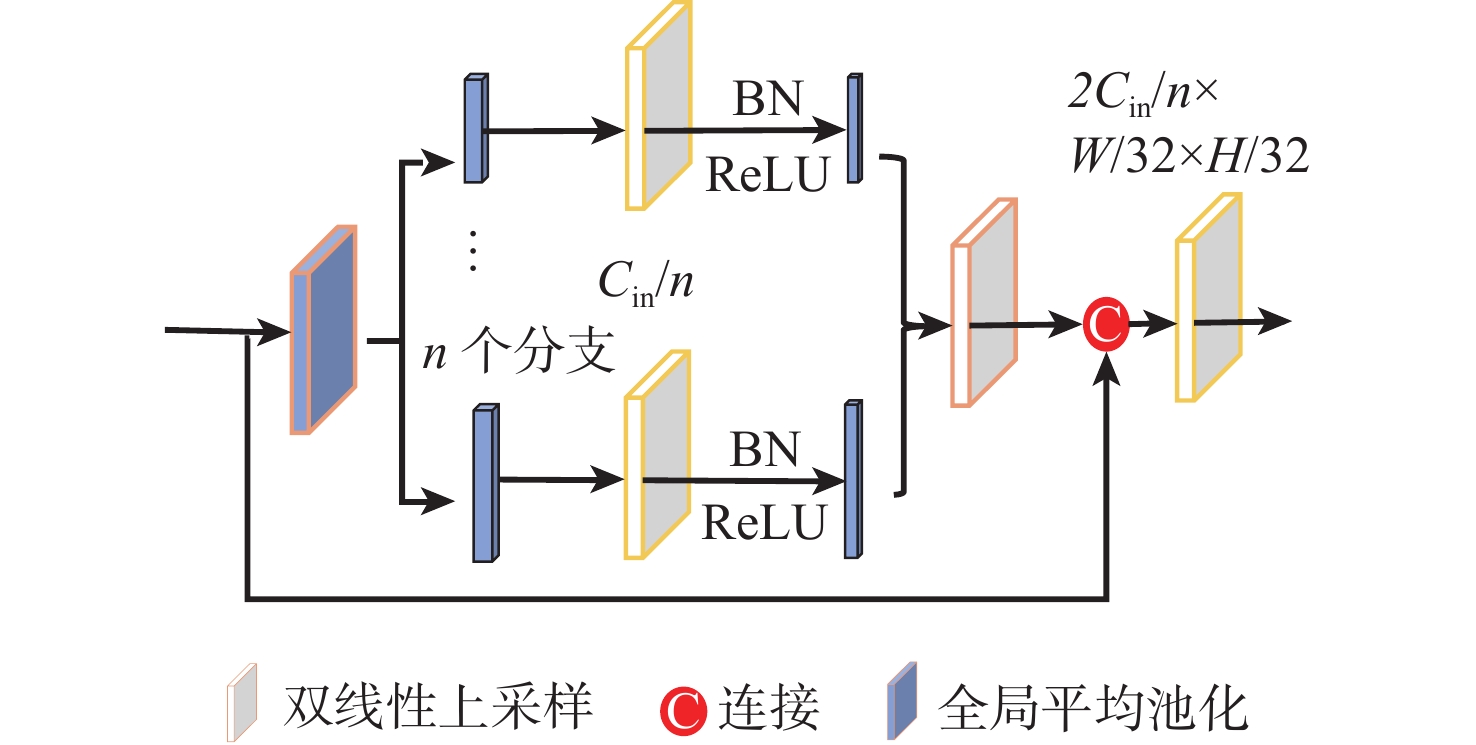
To explore 3D space, mobile robots need to obtain a large amount of scene information, which includes semantic, instance objects, and positional relationships. The accuracy and computational complexity of scene analysis are the two focuses of mobile terminals. Therefore, a spatial information-enhanced multi-task learning method for indoor scene understanding was proposed. This method consists of an encoder with a channel-spatial attention fusion module and a decoder with multi-task heads for semantic segmentation, panoptic segmentation (instance), and orientation estimation. The channel-spatial attention fusion module aims to enhance the modal characteristics of RGB and depth, and the spatial attention mechanism, composed of simple convolutions, can reduce the convergence speed. After fusing with the channel attention mechanism, it further strengthens the position features of global information. The context module of the semantic branch is located after the decoder, providing strong support for pixel-level semantic classification and helping to reduce the model size. A loss function based on hard parameter sharing was designed, enabling balanced training tasks. The influence of an appropriate lightweight backbone network and the number of tasks on improving the performance of scene understanding was discussed. Finally, on the NYUv2 and SUN RGB-D indoor datasets with newly added label annotations, the effectiveness of the proposed multi-task learning method was evaluated. Results show that the comprehensive panoramic segmentation accuracy is improved by 2.93% and 4.87%, respectively.

| [1] |
马素刚, 张子贤, 蒲磊, 等. 结合空间注意力机制的实时鲁棒视觉跟踪[J]. 北京亚洲成人在线一二三四五六区学报, 2024, 50(2): 419-432.
MA S G, ZHANG Z X, PU L, et al. Real-time robust visual tracking based on spatial attention mechanism[J]. Journal of Beijing University of Aeronautics and Astronautics, 2024, 50(2): 419-432(in Chinese).
|
| [2] |
WENGEFELD T, SEICHTER D, LEWANDOWSKI B, et al. Enhancing person perception for mobile robotics by real-time RGB-D person attribute estimation[C]//Proceedings of the IEEE/SICE International Symposium on System Integration. Piscataway: IEEE Press, 2024: 914-921.
|
| [3] |
HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7132-7141.
|
| [4] |
HE Y, XIAO L, SUN Z G, et al. Bimodal feature propagation and fusion for real-time semantic segmentation on RGB-D images[C]//Proceedings of the 7th International Conference on Intelligent Computing and Signal Processing. Piscataway: IEEE Press, 2022: 1897-1902.
|
| [5] |
ISLAM M A, ROCHAN M, BRUCE N D B, et al. Gated feedback refinement network for dense image labeling[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 4877-4885.
|
| [6] |
QUAN T M, HILDEBRAND D G C, JEONG W K. FusionNet: a deep fully residual convolutional neural network for image segmentation in connectomics[J]. Frontiers in Computer Science, 2021, 3: 613981. doi: 10.3389/fcomp.2021.613981
|
| [7] |
FU J, LIU J, TIAN H J, et al. Dual attention network for scene segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 3141-3149.
|
| [8] |
ZHANG R F, LI G B, LI Z, et al. Adaptive context selection for polyp segmentation[C]//Proceedings of the Medical Image Computing and Computer Assisted Intervention. Berlin: Springer, 2020: 253-262.
|
| [9] |
YANG C L, ZHANG C C, YANG X Q, et al. Performance study of CBAM attention mechanism in convolutional neural networks at different depths[C]//Proceedings of the IEEE 18th Conference on Industrial Electronics and Applications. Piscataway: IEEE Press, 2023: 1373-1377.
|
| [10] |
ZOU W B, PENG Y Q, ZHANG Z Y, et al. RGB-D gate-guided edge distillation for indoor semantic segmentation[J]. Multimedia Tools and Applications, 2022, 81(25): 35815-35830. doi: 10.1007/s11042-021-11395-w
|
| [11] |
ZHAO H S, QI X J, SHEN X Y, et al. ICNet for real-time semantic segmentation on high-resolution images[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2018: 418-434.
|
| [12] |
GE W X, YANG X B, JIANG R, et al. CD-CTFM: a lightweight CNN-transformer network for remote sensing cloud detection fusing multiscale features[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024, 17: 4538-4551. doi: 10.1109/JSTARS.2024.3361933
|
| [13] |
VANDENHENDE S, GEORGOULIS S, VAN GOOL L. MTI-Net: multi-scale task interaction networks for multi-task learning[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2020: 527-543.
|
| [14] |
LIN G S, LIU F Y, MILAN A, et al. RefineNet: multi-path refinement networks for dense prediction[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(5): 1228-1242.
|
| [15] |
CAO J M, LENG H C, COHEN-OR D, et al. RGB × D: learning depth-weighted RGB patches for RGB-D indoor semantic segmentation[J]. Neurocomputing, 2021, 462: 568-580. doi: 10.1016/j.neucom.2021.08.009
|
| [16] |
CHEN L Z, LIN Z, WANG Z Q, et al. Spatial information guided convolution for real-time RGBD semantic segmentation[J]. IEEE Transactions on Image Processing, 2021, 30: 2313-2324.
|
| [17] |
BORSE S, PARK H, CAI H, et al. Panoptic, instance and semantic relations: a relational context encoder to enhance panoptic segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 1259-1269.
|
| [18] |
XIONG Y W, LIAO R J, ZHAO H S, et al. A unified panoptic segmentation network[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 8810-8818.
|
| [19] |
MOHAN R, VALADA A. EfficientPS: efficient panoptic segmentation[J]. International Journal of Computer Vision, 2021, 129(5): 1551-1579. doi: 10.1007/s11263-021-01445-z
|
| [20] |
CHENG B W, COLLINS M D, ZHU Y K, et al. Panoptic-DeepLab: a simple, strong, and fast baseline for bottom-up panoptic segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 12472-12482.
|
| [21] |
ZOU Q, DU X Z, LIU Y Z, et al. Dynamic path planning and motion control of microrobotic swarms for mobile target tracking[J]. IEEE Transactions on Automation Science and Engineering, 2023, 20(4): 2454-2468. doi: 10.1109/TASE.2022.3207289
|
| [22] |
MAHFOUDI M N, TURLETTI T, PARMENTELAT T, et al. ORION: orientation estimation using commodity Wi-Fi[C]//Proceedings of the IEEE International Conference on Communications Workshops. Piscataway: IEEE Press, 2017: 1233-1238.
|
| [23] |
CHRISTIE G, ABUJDER R R R M, FOSTER K, et al. Learning geocentric object pose in oblique monocular images[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 14500-14508.
|
| [24] |
TANG H Y, LIU J N, ZHAO M, et al. Progressive layered extraction (PLE): a novel multi-task learning (MTL) model for personalized recommendations[C]//Proceedings of the 14th ACM Conference on Recommender Systems. New York: ACM, 2020: 269-278.
|
| [25] |
LIU X D, HE P C, CHEN W Z, et al. Multi-task deep neural networks for natural language understanding[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 4487-4496.
|
| [26] |
WU P, GUO R Z, TONG X Z, et al. Link-RGBD: cross-guided feature fusion network for RGBD semantic segmentation[J]. IEEE Sensors Journal, 2022, 22(24): 24161-24175. doi: 10.1109/JSEN.2022.3218601
|
| [27] |
ZHANG Y, XIONG C Y, LIU J J, et al. Spatial information-guided adaptive context-aware network for efficient RGB-D semantic segmentation[J]. IEEE Sensors Journal, 2023, 23(19): 23512-23521. doi: 10.1109/JSEN.2023.3304637
|
| [28] |
HUANG L, GUO H. Research on multi-task learning method based on causal features[C]//Proceedings of the International Conference on Image Processing, Computer Vision and Machine Learning. Piscataway: IEEE Press, 2023: 924-927.
|
| [29] |
BEYER L, HERMANS A, LEIBE B. Biternion Nets: continuous head pose regression from discrete training labels[J]. Pattern Recognition, 2015, 9358: 157-168.
|
| [30] |
SILBERMAN N, HOIEM D, KOHLI P, et al. Indoor segmentation and support inference from RGBD images[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2012: 746-760.
|
| [31] |
SEICHTER D, FISCHEDICK S B, KÖHLER M, et al. Efficient multi-task RGB-D scene analysis for indoor environments[C]//Proceedings of the International Joint Conference on Neural Networks. Piscataway: IEEE Press, 2022: 1-10.
|
| [32] |
SONG S R, LICHTENBERG S P, XIAO J X. SUN RGB-D: a RGB-D scene understanding benchmark suite[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2015: 567-576.
|

Figures(4) / Tables(6)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@cqjj8.com
Supported by:
Beijing Renhe Information Technology Co., Ltd.





 DownLoad:
DownLoad: