| Citation: | CHENG D Q,FAN S M,QIAN J S,et al. Coordinate-aware attention-based multi-frame self-supervised monocular depth estimation[J]. Journal of Beijing University of Aeronautics and Astronautics,2025,51(7):2218-2228 (in Chinese) doi: 10.13700/j.bh.1001-5965.2023.0417

|
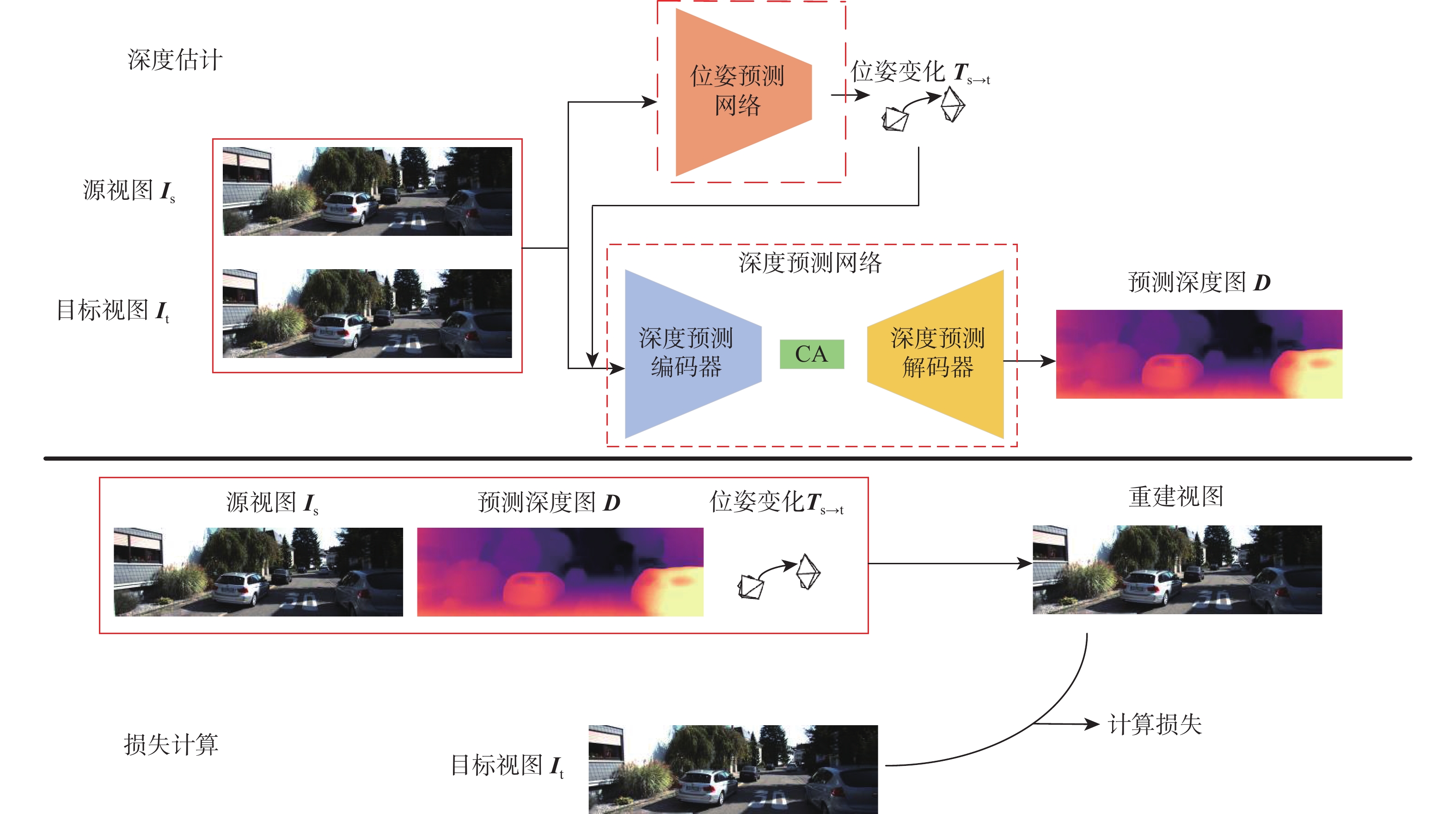
A novel multi-frame self-supervised single-image depth estimation technique based on coordinate-aware attention has been presented to tackle the issue of hazy depth prediction near object edges in single-image depth estimation methods. Firstly, a coordinate-aware attention module is proposed to enhance the output features of the bottom layer of the encoder and improve the feature utilization of the cost volume. To improve the object edges in depth prediction results, a new pixel-shuffle-based depth prediction decoder is also suggested. This decoder can efficiently separate the multi-object fusion features in low-resolution encoder features. Experimental results on the KITTI and Cityscapes datasets demonstrate that the proposed method is superior to current mainstream methods, significantly improving subjective visual effects and objective evaluation indicators, especially with better depth prediction performance in object edge details.

| [1] |
李杰, 李一轩, 吴天生, 等. 基于FPGA无人机影像快速低功耗高精度三维重建[J]. 北京亚洲成人在线一二三四五六区学报, 2021, 47(3): 486-499.
LI J, LI Y X, WU T S, et al. Fast, low-power and high-precision 3D reconstruction of UAV images based on FPGA[J]. Journal of Beijing University of Aeronautics and Astronautics, 2021, 47(3): 486-499(in Chinese).
|
| [2] |
ZHOU T H, BROWN M, SNAVELY N, et al. Unsupervised learning of depth and ego-motion from video[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 6612-6619.
|
| [3] |
GODARD C, MAC AODHA O, FIRMAN M, et al. Digging into self-supervised monocular depth estimation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 3827-3837.
|
| [4] |
WATSON J, MAC AODHA O, PRISACARIU V, et al. The temporal opportunist: self-supervised multi-frame monocular depth[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 1164-1174.
|
| [5] |
GUIZILINI V, AMBRUŞ R, CHEN D, et al. Multi-frame self-supervised depth with Transformers[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 160-170.
|
| [6] |
SHI W Z, CABALLERO J, HUSZÁR F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 1874-1883.
|
| [7] |
GEIGER A, LENZ P, STILLER C, et al. Vision meets robotics: the KITTI dataset[J]. The International Journal of Robotics Research, 2013, 32(11): 1231-1237. doi: 10.1177/0278364913491297
|
| [8] |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778.
|
| [9] |
HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 2261-2269.
|
| [10] |
HOU Q B, ZHOU D Q, FENG J S. Coordinate attention for efficient mobile network design[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 13708-13717.
|
| [11] |
EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network[EB/OL]. (2014-06-09)[2023-06-01]. http://arxiv.org/abs/1406.2283v1.
|
| [12] |
ZOU Y L, JI P, TRAN Q H, et al. Learning monocular visual odometry via self-supervised long-term modeling[C]//Proceedings of the 16th European Conference on Computer Vision. Berlin: Springer, 2020: 710-727.
|
| [13] |
GUIZILINI V, HOU R, LI J, et al. Semantically-guided representation learning for self-supervised monocular depth[EB/OL]. (2020-02-27)[2023-06-01]. http://arxiv.org/abs/2002.12319v1.
|
| [14] |
KLINGNER M, TERMÖHLEN J A, MIKOLAJCZYK J, et al. Self-supervised monocular depth estimation: solving the dynamic object problem by semantic guidance[C]//Proceedings of the 16th European Conference on Computer Vision. Berlin: Springer, 2020: 582-600.
|
| [15] |
LEE S, IM S, LIN S, et al. Learning monocular depth in dynamic scenes via instance-aware projection consistency[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35(3): 1863-1872. doi: 10.1609/aaai.v35i3.16281
|
| [16] |
POGGI M, ALEOTTI F, TOSI F, et al. On the uncertainty of self-supervised monocular depth estimation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 3224-3234.
|
| [17] |
PATIL V, VAN GANSBEKE W, DAI D X, et al. Don’t forget the past: recurrent depth estimation from monocular video[J]. IEEE Robotics and Automation Letters, 2020, 5(4): 6813-6820. doi: 10.1109/LRA.2020.3017478
|
| [18] |
CHOI J, JUNG D, LEE D, et al. SAFENet: self-supervised monocular depth estimation with semantic-aware feature extraction[EB/OL]. (2020-11-29)[2023-06-01]. http://arxiv.org/abs/2010.02893v3.
|
| [19] |
WANG J D, SUN K, CHENG T H, et al. Deep high-resolution representation learning for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(10): 3349-3364. doi: 10.1109/TPAMI.2020.2983686
|
| [20] |
YAN J X, ZHAO H, BU P H, et al. Channel-wise attention-based network for self-supervised monocular depth estimation[C]//Proceedings of the International Conference on 3D Vision. Piscataway: IEEE Press, 2021: 464-473.
|
| [21] |
JUNG H, PARK E, YOO S. Fine-grained semantics-aware representation enhancement for self-supervised monocular depth estimation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 12622-12632.
|
| [22] |
ZHANG N, NEX F, VOSSELMAN G, et al. Lite-Mono: a lightweight CNN and transformer architecture for self-supervised monocular depth estimation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2023: 18537-18546.
|
| [23] |
SURI Z K. Pose constraints for consistent self-supervised monocular depth and ego-motion[C]//Proceedings of the Scandinavian Conference on Image Analysis. Berlin: Springer, 2023: 340-353.
|
| [24] |
BOULAHBAL H, VOICILA A, COMPORT A. STDepthFormer: predicting spatio-temporal depth from video with a self-supervised transformer model[EB/OL]. (2023-05-02)[2023-06-01]. http://arxiv.org/abs/2303.01196v1.
|
| [25] |
LIU Y X, XU Z H, HUANG H Y, et al. FSNet: redesign self-supervised MonoDepth for full-scale depth prediction for autonomous driving[EB/OL]. (2023-04-21)[2023-06-01]. http://arxiv.org/abs/2304.10719v1.
|
| [26] |
SAUNDERS K, VOGIATZIS G, MANSO L J. Self-supervised monocular depth estimation: let’s talk about the weather[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2023: 8873-8883.
|
| [27] |
WANG B Y, WANG S, YE D, et al. Deep neighbor layer aggregation for lightweight self-supervised monocular depth estimation[EB/OL]. [2023-06-01]. http://arxiv.org/abs/2309.09272v2.
|
Figures(7) / Tables(4)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@cqjj8.com
Supported by:
Beijing Renhe Information Technology Co., Ltd.





 DownLoad:
DownLoad:





