| Citation: | JIANG X,XU X,SHEN F M,et al. Efficient weakly-supervised video moment retrieval algorithm without multimodal fusion[J]. Journal of Beijing University of Aeronautics and Astronautics,2025,51(7):2384-2393 (in Chinese) doi: 10.13700/j.bh.1001-5965.2023.0379

|
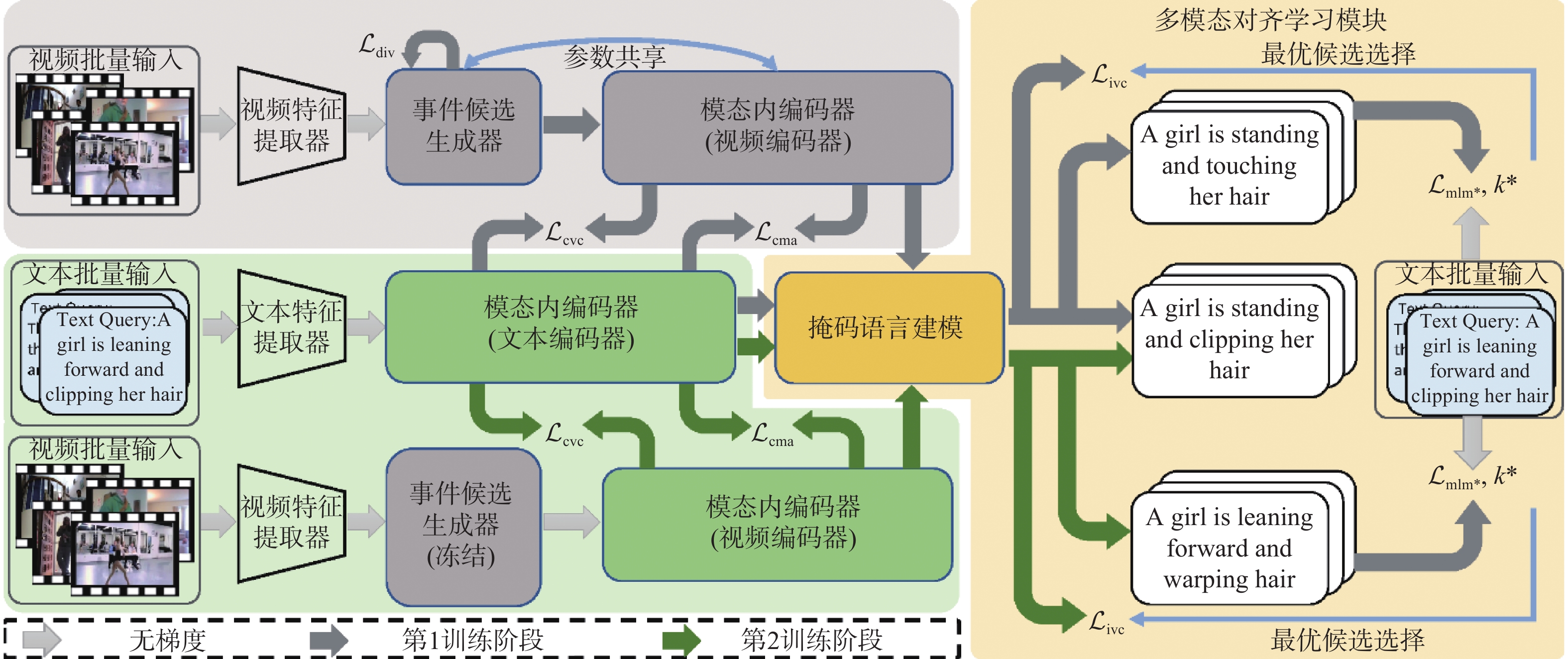
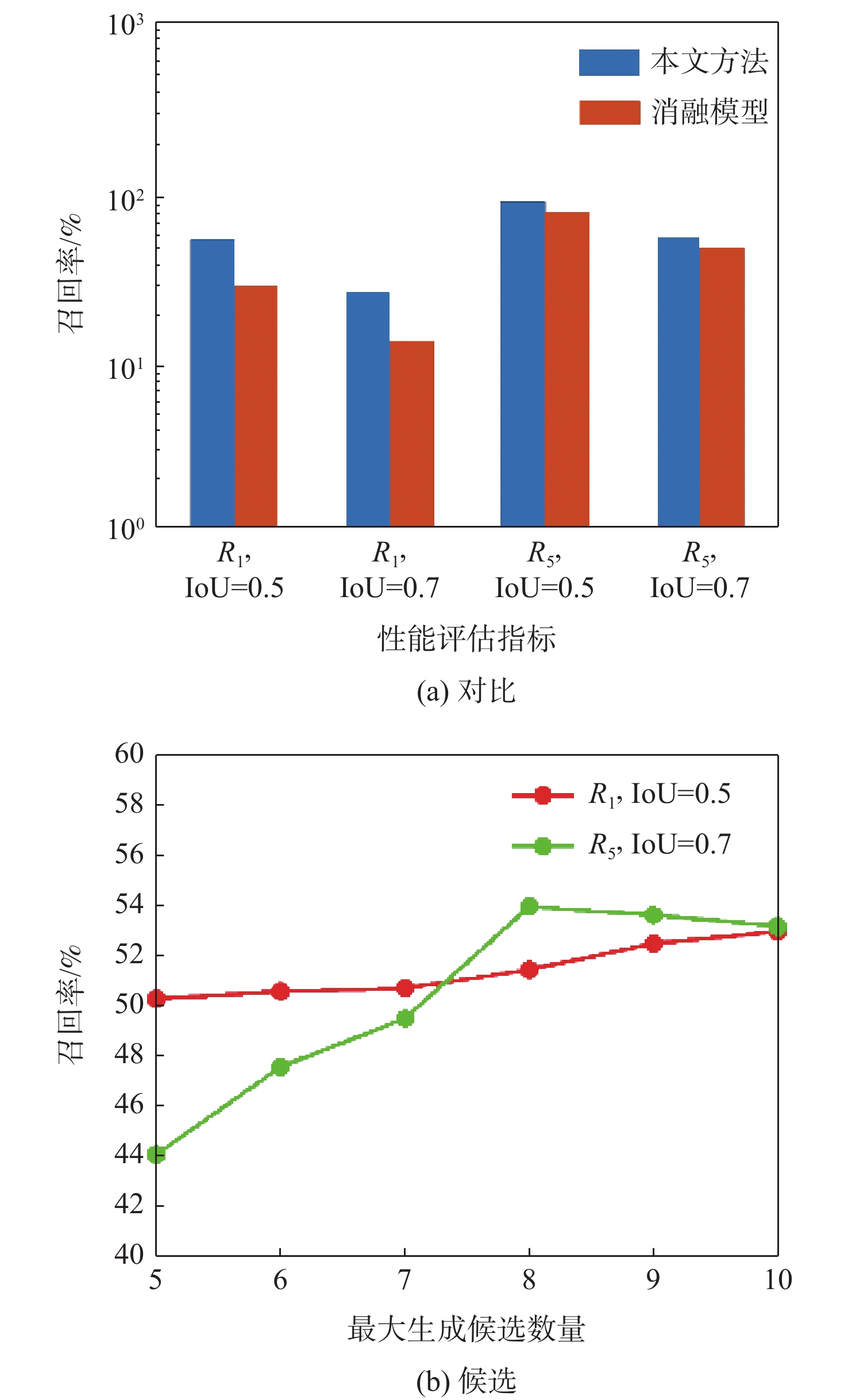
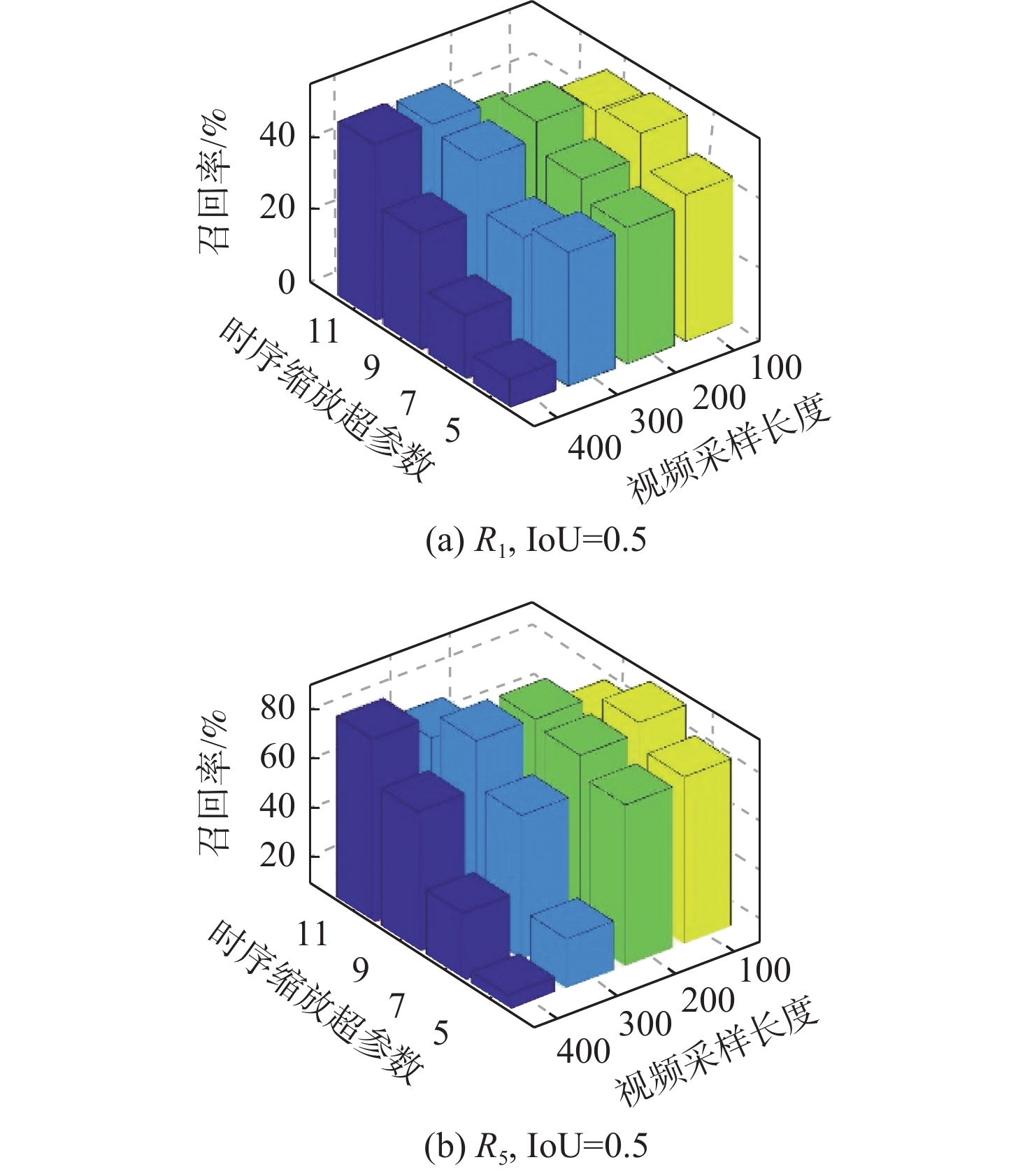
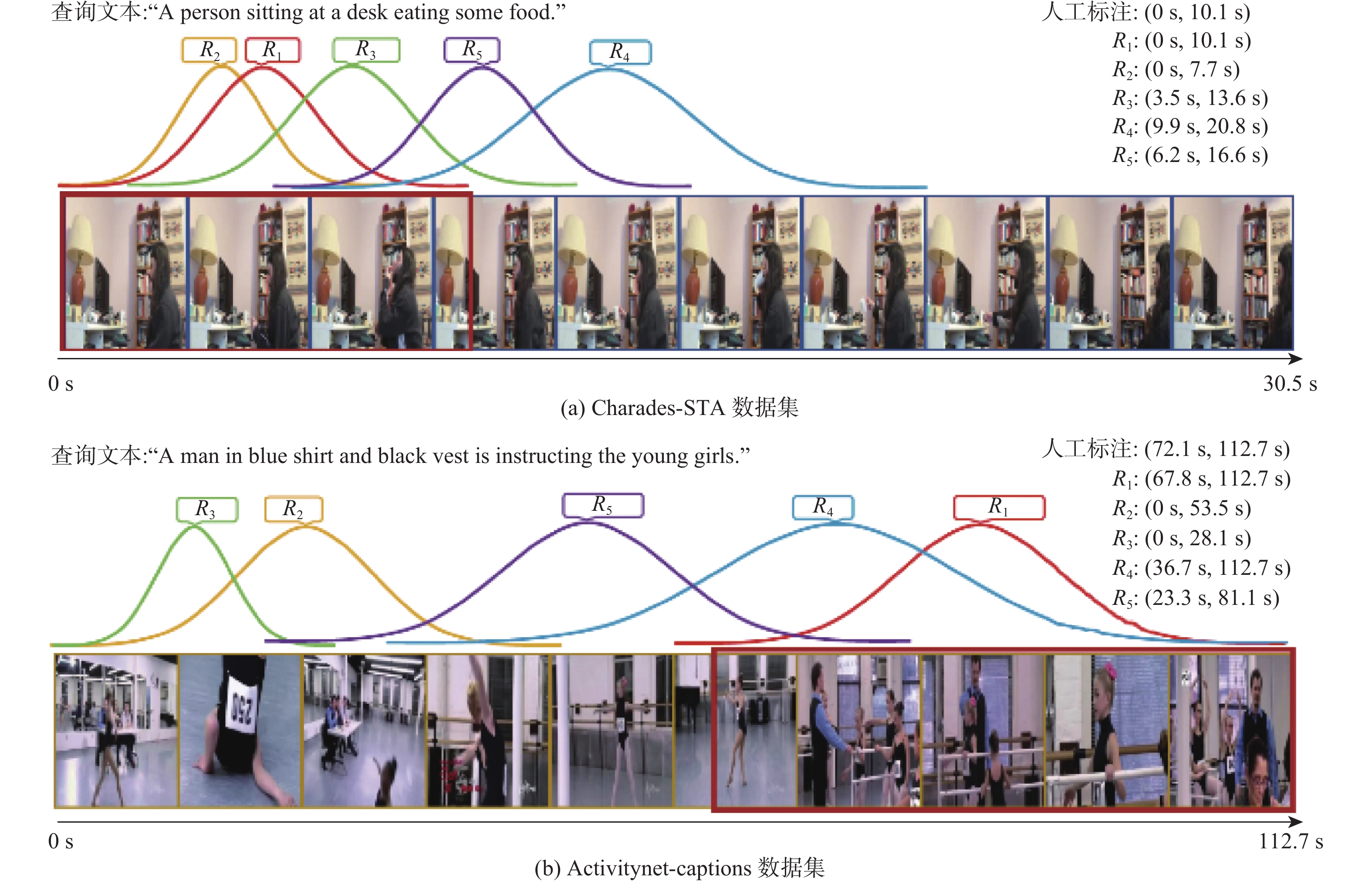
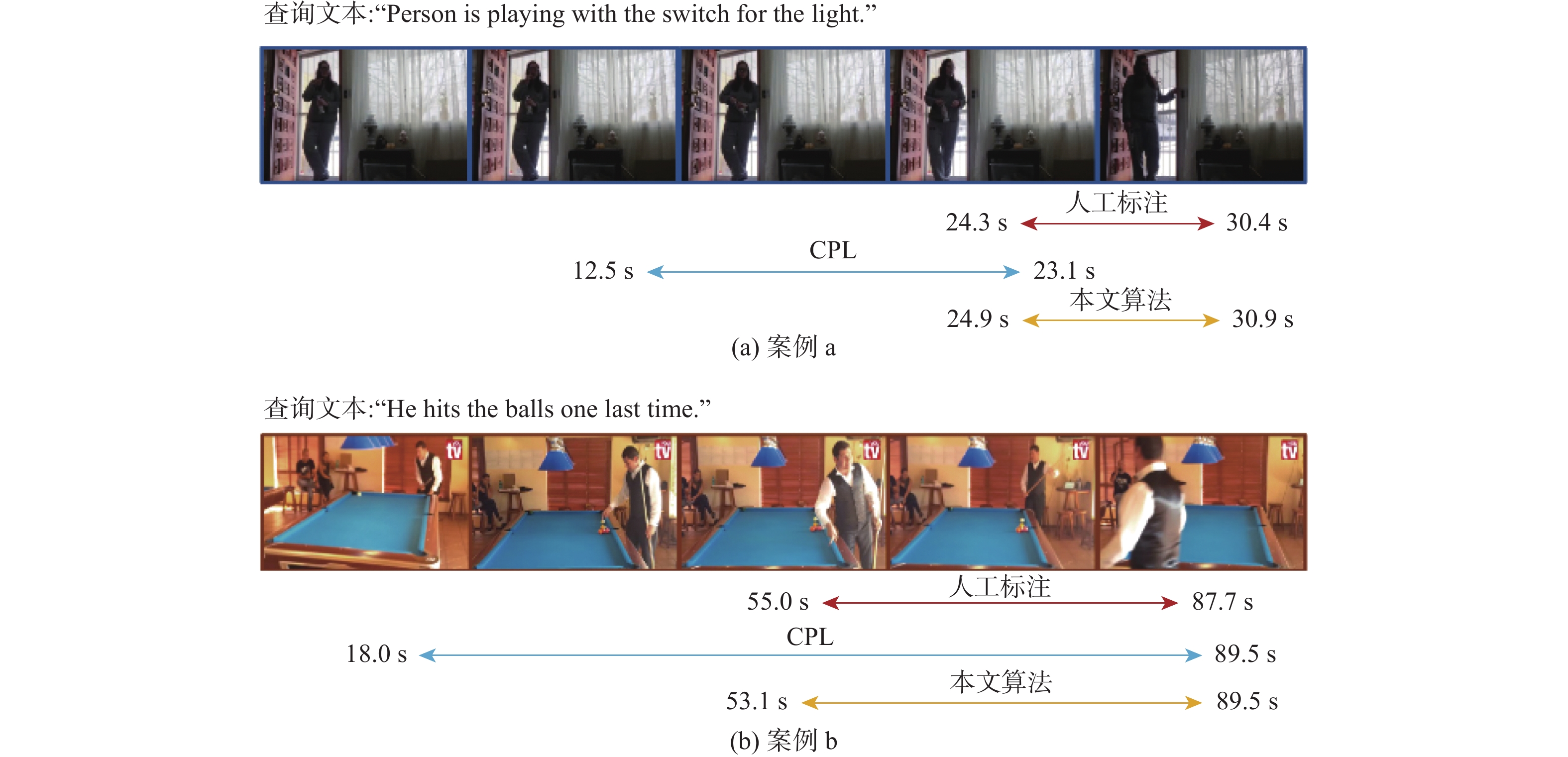
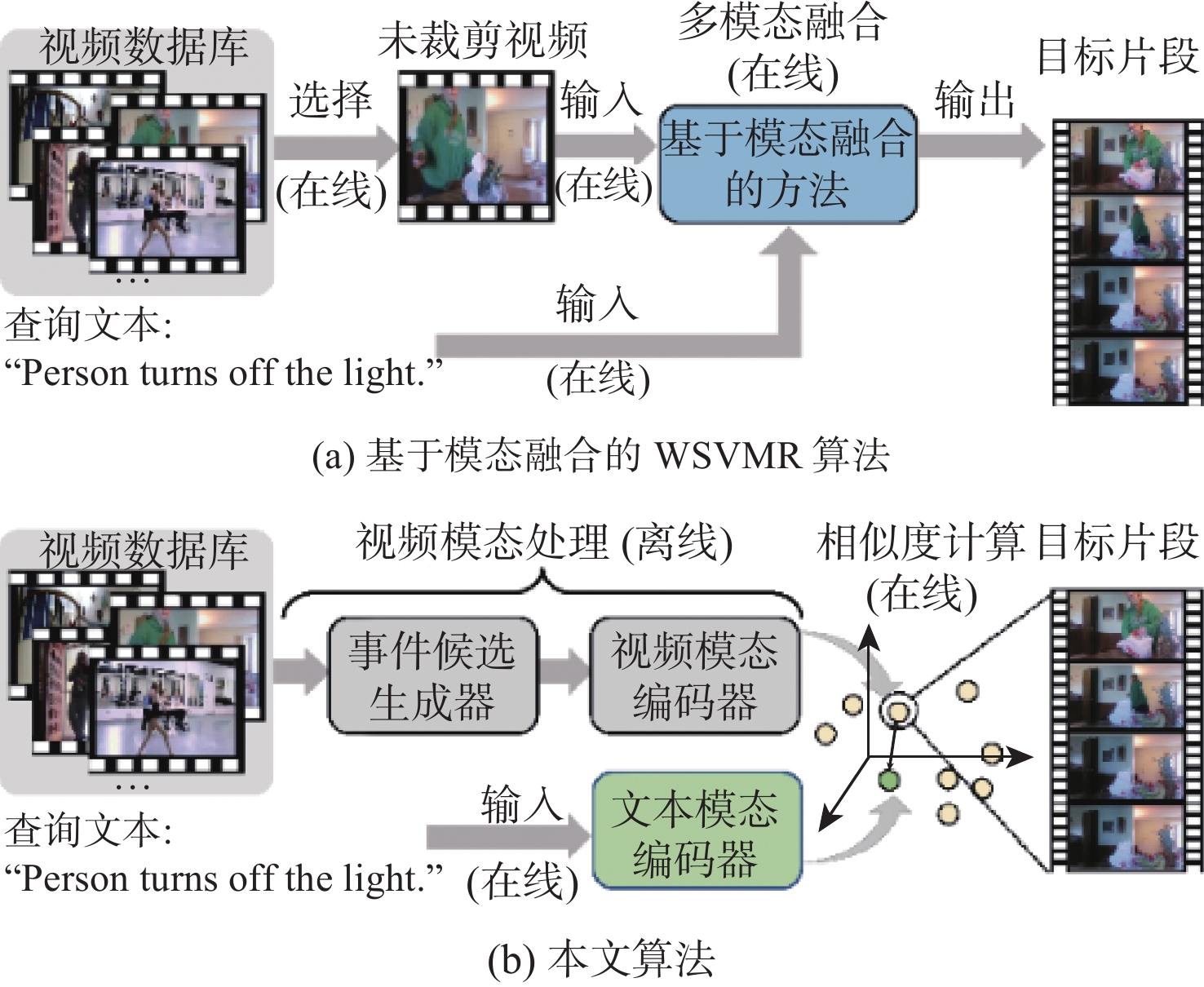
The weakly-supervised video moment retrieval (WSVMR) task retrieves in and out points of specific events from untrimmed videos based on natural language query text, using a deep learning algorithm model trained through video and natural language text matching relationships. Most existing WSVMR algorithms use multimodal fusion mechanisms to understand video content for moment retrieval. However, the cross-modal interactions required for effective fusion are quite complex, and this process can only be initiated once a clear user query is received. These hinder the operational efficiency of these algorithms, limiting their deployment in multimedia applications. To address this issue, a novel fusion-free multimodal alignment network (FMAN) algorithm for achieving rapid WSVMR was proposed. By restricting complex cross-modal interaction computation in the training phase, this algorithm enables offline encoding of both video and text data by the model, thereby significantly improving the inference speed of video moment retrieval. Experimental results on Charades-STA and ActivityNet-Captions datasets show FMAN’s superior retrieval performance and efficiency compared to existing methods. The experiment on retrieval performance metrics, specifically recall rates (

| [1] |
GAO J Y, SUN C, YANG Z H, et al. TALL: temporal activity localization via language query[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 5277-5285.
|
| [2] |
ZHANG S Y, PENG H W, FU J L, et al. Learning 2D temporal adjacent networks for moment localization with natural language[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 12870-12877. doi: 10.1609/aaai.v34i07.6984
|
| [3] |
MUN J, CHO M, HAN B. Local-global video-text interactions for temporal grounding[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 10807-10816.
|
| [4] |
JIANG X, XU X, ZHANG J R, et al. SDN: semantic decoupling network for temporal language grounding[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(5): 6598-6612. doi: 10.1109/TNNLS.2022.3211850
|
| [5] |
CUI R, QIAN T W, PENG P, et al. Video moment retrieval from text queries via single frame annotation[C]//Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2022: 1033-1043.
|
| [6] |
WANG L, MITTAL G, SAJEEV S, et al. ProTéGé: untrimmed pretraining for video temporal grounding by video temporal grounding[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2023: 6575-6585.
|
| [7] |
JIANG X, ZHOU Z L, XU X, et al. Faster video moment retrieval with point-level supervision[EB/OL]. (2023-01-23)[2023-02-01]. http://arxiv.org/abs/2305.14017v1.
|
| [8] |
JI W, LIANG R J, ZHENG Z D, et al. Are binary annotations sufficient? video moment retrieval via hierarchical uncertainty-based active learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2023: 23013-23022.
|
| [9] |
ZHENG M H, HUANG Y J, CHEN Q C, et al. Weakly supervised temporal sentence grounding with Gaussian-based contrastive proposal learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 15534-15543.
|
| [10] |
YANG W F, ZHANG T Z, ZHANG Y D, et al. Local correspondence network for weakly supervised temporal sentence grounding[J]. IEEE Transactions on Image Processing, 2021, 30: 3252-3262. doi: 10.1109/TIP.2021.3058614
|
| [11] |
CAI W T, HUANG J B, GONG S G. Hybrid-learning video moment retrieval across multi-domain labels[EB/OL]. (2022-12-23)[2023-02-01]. http://arxiv.org/abs/2406.01791.
|
| [12] |
CHEN J M, LUO W X, ZHANG W, et al. Explore inter-contrast between videos via composition for weakly supervised temporal sentence grounding[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2022, 36(1): 267-275. doi: 10.1609/aaai.v36i1.19902
|
| [13] |
WU Q, CHEN Y F, HUANG N, et al. Weakly-supervised cerebrovascular segmentation network with shape prior and model indicator[C]//Proceedings of the International Conference on Multimedia Retrieval. New York: ACM, 2022: 668-676.
|
| [14] |
丁家满, 刘楠, 周蜀杰, 等. 基于正则化的半监督弱标签分类算法[J]. 计算机学报, 2022, 45(1): 69-81. doi: 10.11897/SP.J.1016.2022.00069
DING J M, LIU N, ZHOU S J, et al. Semi-supervised weak-label classification method by regularization[J]. Chinese Journal of Computers, 2022, 45(1): 69-81(in Chinese). doi: 10.11897/SP.J.1016.2022.00069
|
| [15] |
LIN Z J, ZHAO Z, ZHANG Z, et al. Weakly-supervised video moment retrieval via semantic completion network[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 11539-11546. doi: 10.1609/aaai.v34i07.6820
|
| [16] |
JIANG X, XU X, ZHANG J R, et al. Semi-supervised video paragraph grounding with contrastive encoder[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 2456-2465.
|
| [17] |
XU X, WANG T, YANG Y, et al. Cross-modal attention with semantic consistence for image–text matching[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(12): 5412-5425. doi: 10.1109/TNNLS.2020.2967597
|
| [18] |
JIANG X, XU X, CHEN Z G, et al. DHHN: dual hierarchical hybrid network for weakly-supervised audio-visual video parsing[C]//Proceedings of the 30th ACM International Conference on Multimedia. New York: ACM, 2022: 719-727.
|
| [19] |
刘耀胜, 廖育荣, 林存宝, 等. 基于特征融合与抗遮挡的卫星视频目标跟踪算法[J]. 北京亚洲成人在线一二三四五六区学报, 2022, 48(12): 2537-2547.
LIU Y S, LIAO Y R, LIN C B, et al. Feature-fusion and anti-occlusion based target tracking method for satellite videos[J]. Journal of Beijing University of Aeronautics and Astronautics, 2022, 48(12): 2537-2547(in Chinese).
|
| [20] |
张燕咏, 张莎, 张昱, 等. 基于多模态融合的自动驾驶感知及计算[J]. 计算机研究与发展, 2020, 57(9): 1781-1799. doi: 10.7544/issn1000-1239.2020.20200255
ZHANG Y Y, ZHANG S, ZHANG Y, et al. Multi-modality fusion perception and computing in autonomous driving[J]. Journal of Computer Research and Development, 2020, 57(9): 1781-1799(in Chinese). doi: 10.7544/issn1000-1239.2020.20200255
|
| [21] |
JIANG X, XU X, ZHANG J R, et al. GTLR: graph-based transformer with language reconstruction for video paragraph grounding[C]//Proceedings of the IEEE International Conference on Multimedia and Expo. Piscataway: IEEE Press, 2022: 1-6.
|
| [22] |
CARREIRA J, ZISSERMAN A. Quo vadis, action recognition? a new model and the kinetics dataset[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 4724-4733.
|
| [23] |
PENNINGTON J, SOCHER R, MANNING C. Glove: global vectors for word representation[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Stroudsburg: USAACL, 2014: 1532-1543.
|
| [24] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[EB/OL]. (2017-06-12)[2023-02-01]. http://arxiv.org/abs/1706.03762.
|
| [25] |
KRISHNA R, KENJI H T, REN F, et al. Dense-captioning events in videos[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 706-715.
|
| [26] |
KINGMA D P, BA J, HAMMAD M M. Adam: a method for stochastic optimization[EB/OL]. (2017-01-30)[2023-02-01]. http://arxiv.org/abs/1412.6980v9.
|
| [27] |
LI H J, SHU X J, HE S N, et al. D3G: exploring Gaussian prior for temporal sentence grounding with glance annotation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2023: 13688-13700.
|
| [28] |
MA F, ZHU L C, YANG Y. Weakly supervised moment localization with decoupled consistent concept prediction[J]. International Journal of Computer Vision, 2022, 130(5): 1244-1258. doi: 10.1007/s11263-022-01600-0
|
Figures(7) / Tables(3)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@cqjj8.com
Supported by:
Beijing Renhe Information Technology Co., Ltd.





 DownLoad:
DownLoad: