| Citation: | ZHU X Q,WANG T,RUAN X G,et al. Gait learning method of quadruped robot based on policy distillation[J]. Journal of Beijing University of Aeronautics and Astronautics,2025,51(2):428-439 (in Chinese) doi: 10.13700/j.bh.1001-5965.2023.0069

|
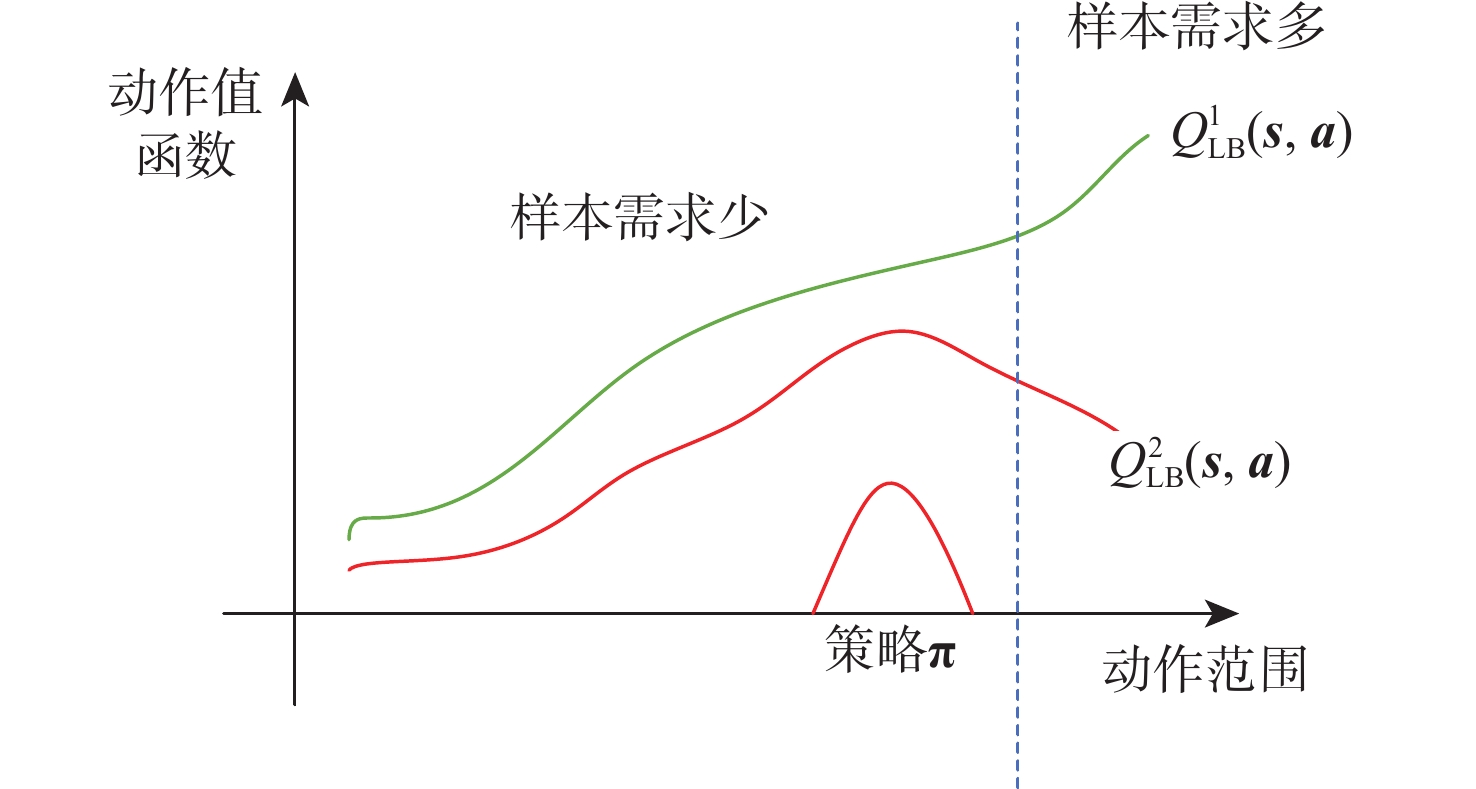
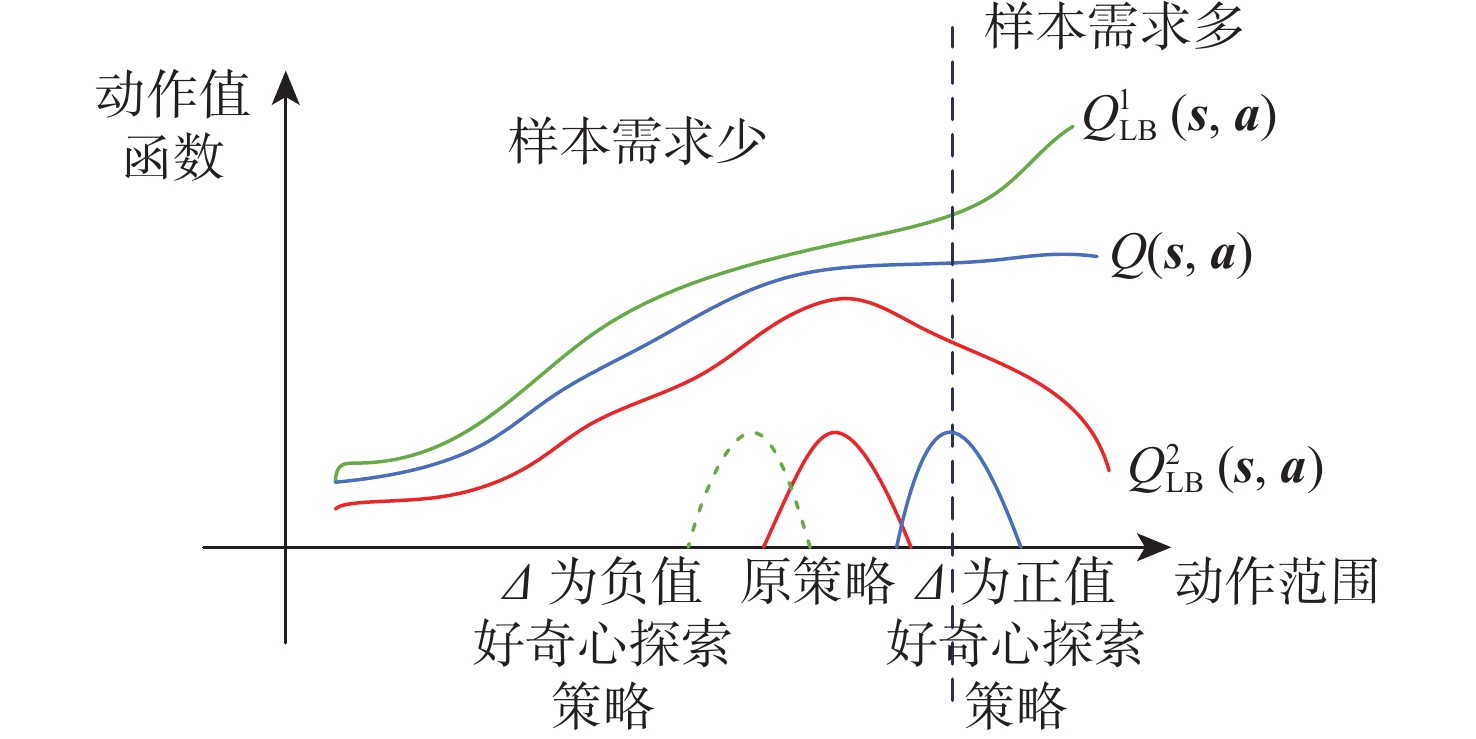
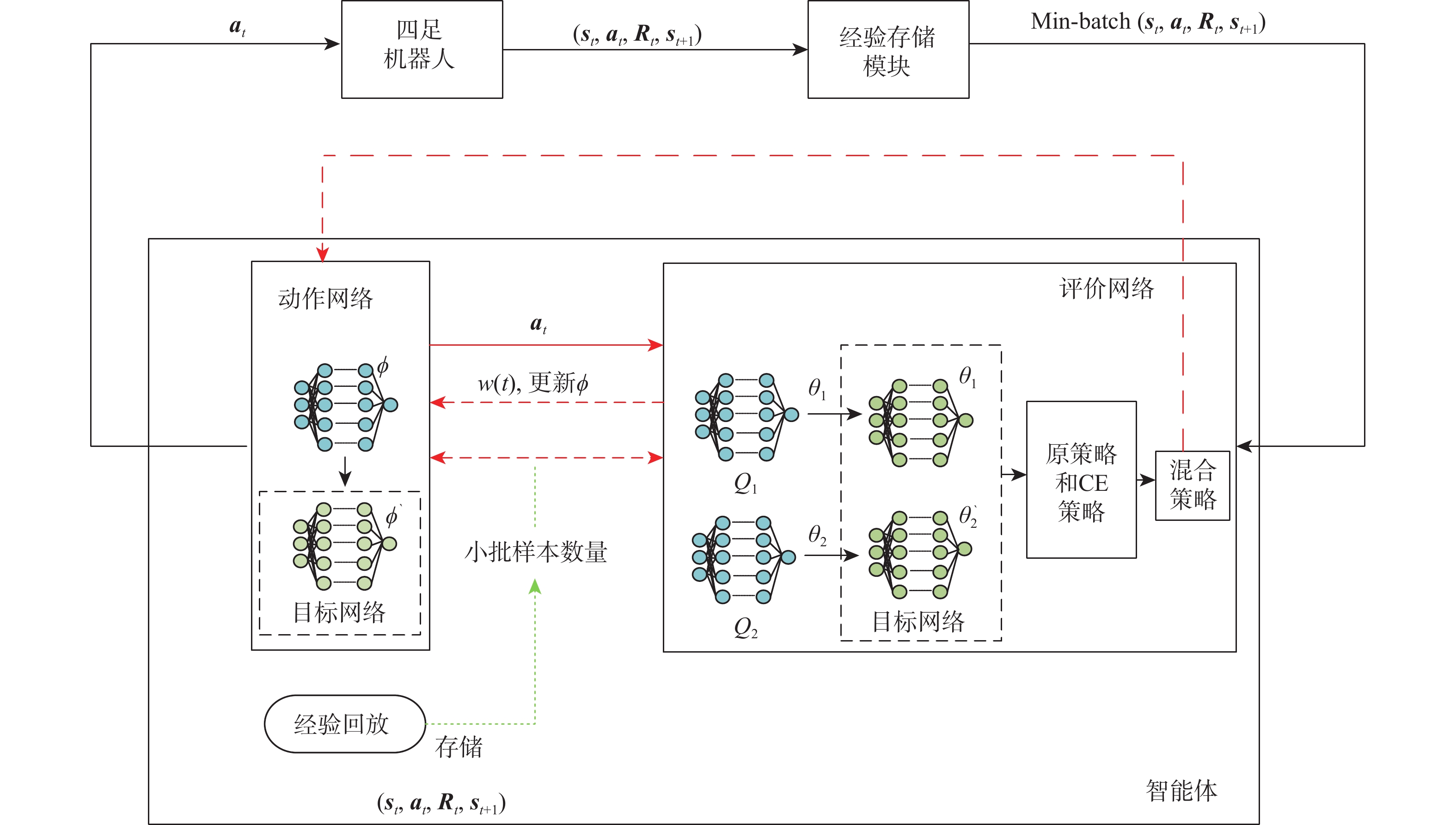
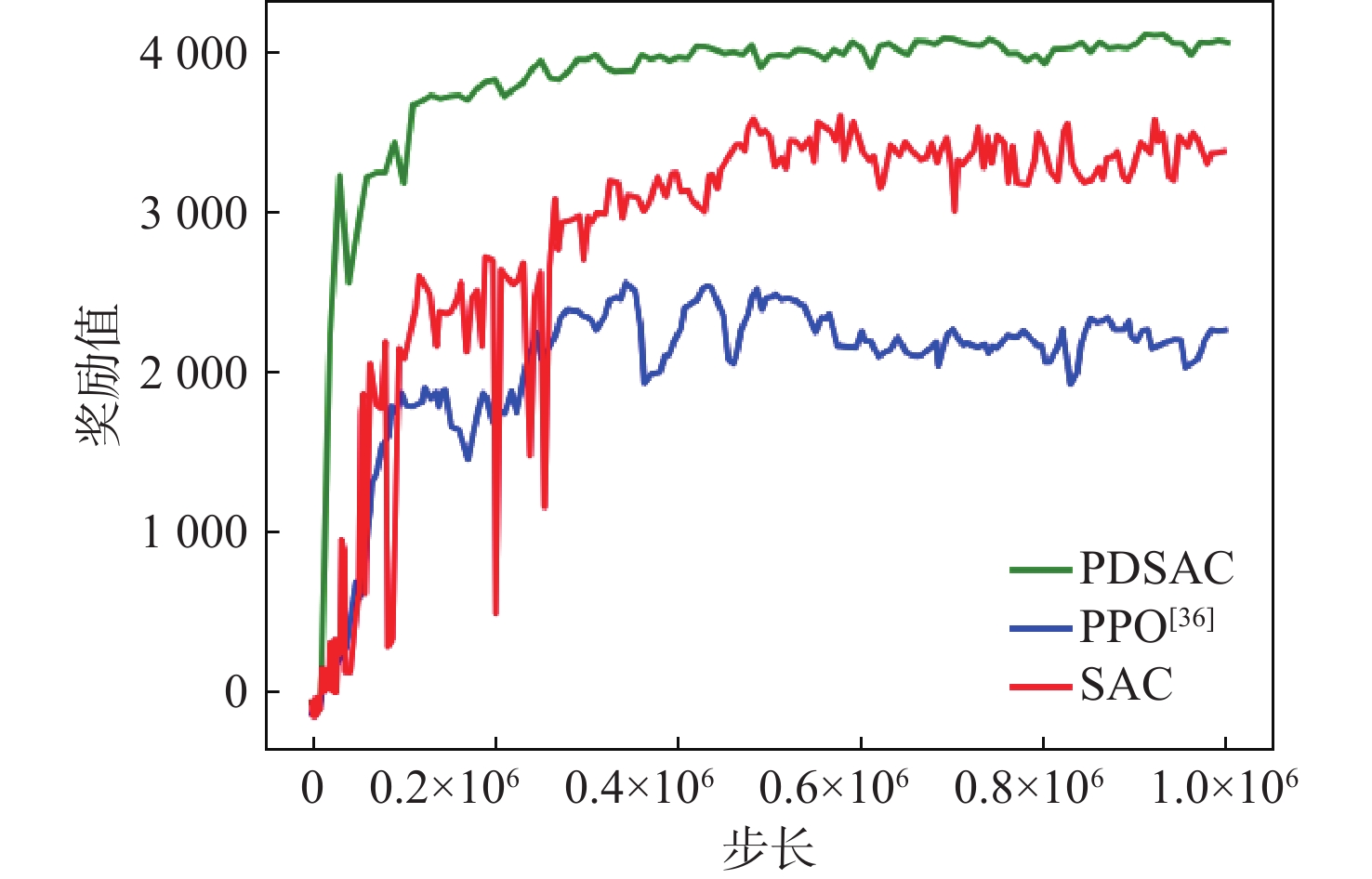
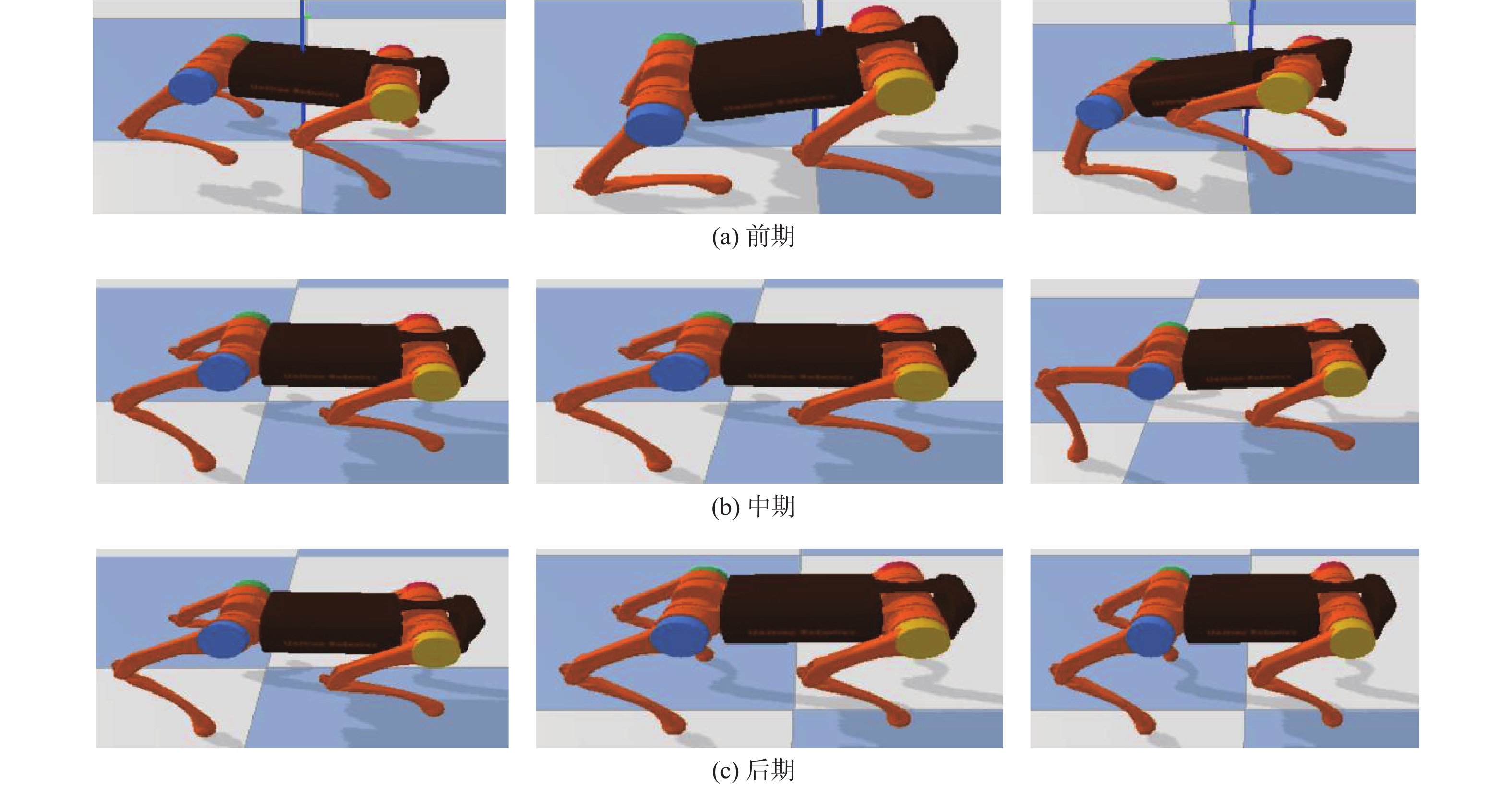
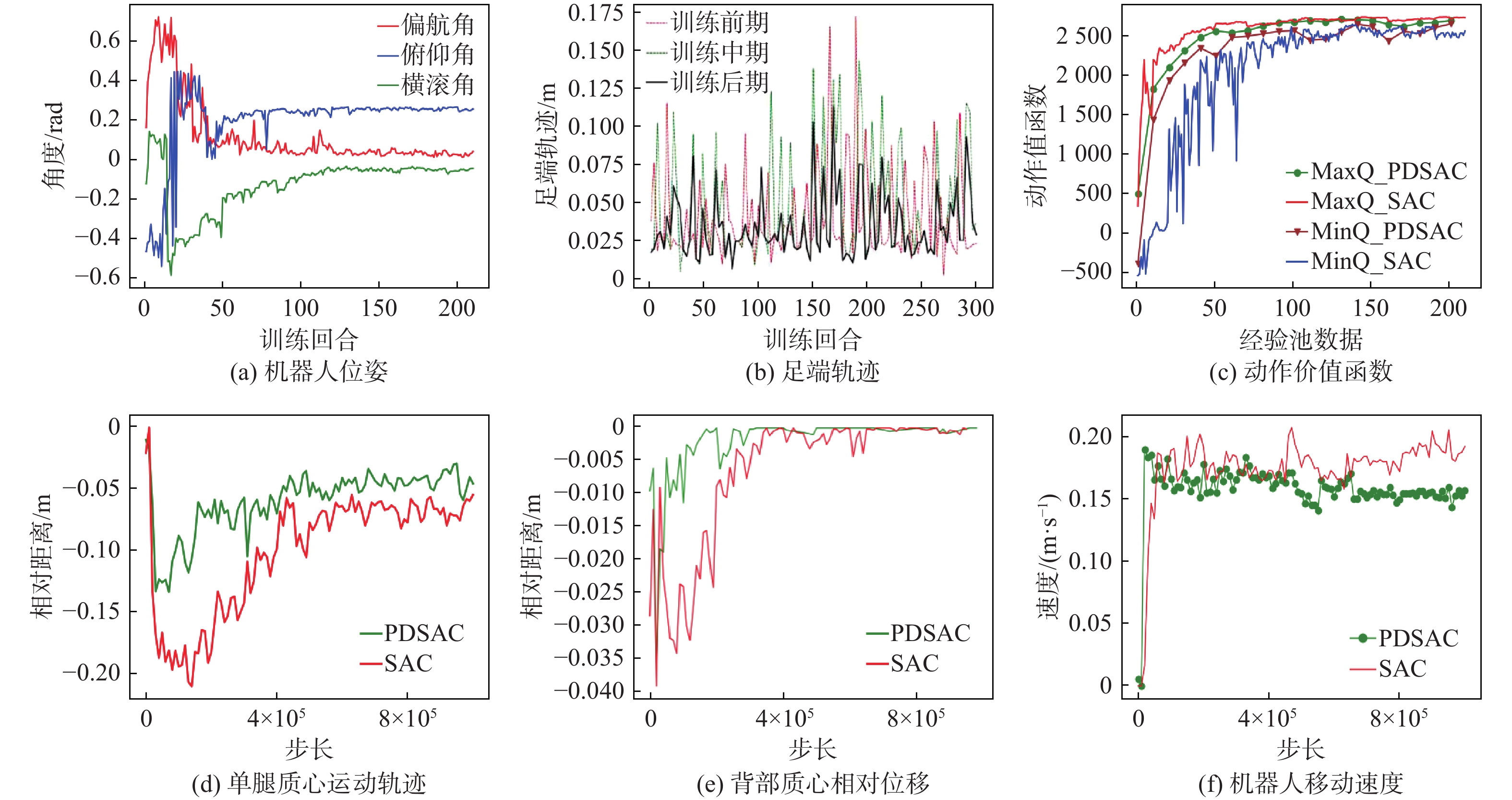
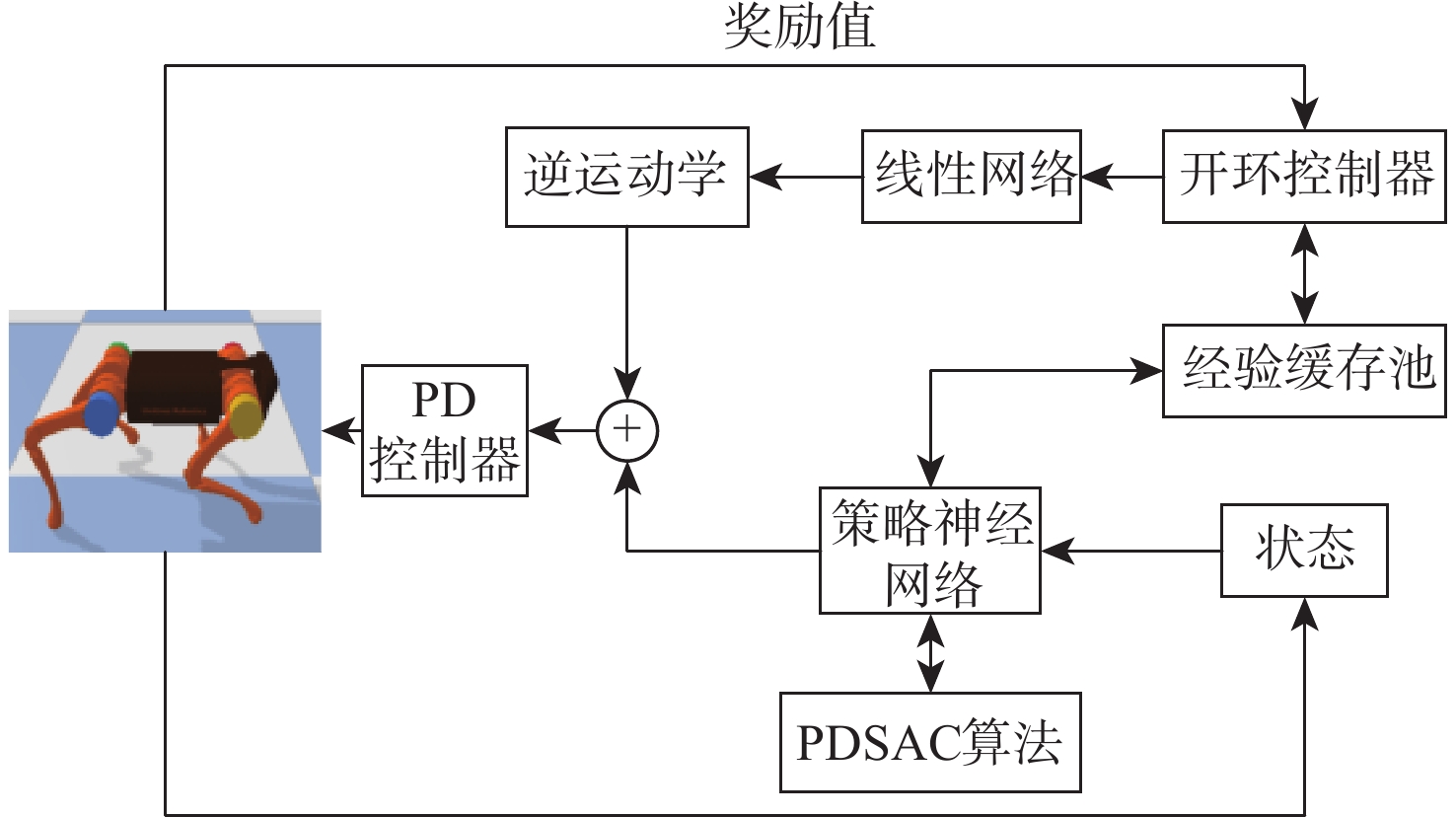
Reinforcement learning algorithm represented by flexible action evaluation (SAC) has been successful in reproducing the motor skills of higher animals. This framework combines strategy search and state action value function. However, the agent use strategy exploration is greedy, and the Q value function of evaluation network estimation uses low valuation. This paper proposes a policy distillation (PD) soft actor-critic (PDSAC) algorithm that integrates PD and SAC algorithms to enable agents to adopt better policies. This algorithm allows the agent to explore using hybrid policies and speeds up the convergence of the reward function from reinforcement learning. To validate the proposed algorithm, Theoretical proof that the PDSAC algorithm improves the efficiency of policy exploration and validation in quadruped robot gait learning tasks. According to simulation results, the PDSAC outperforms the SAC in the gait learning task, achieving a 40% increase in convergence speed and a 26.7% improvement in the reward value function.

| [1] |
LEVINE S, FINN C, DARRELL T, et al. End-to-end training of deep visuomotor policies[EB/OL]. (2015-04-02)[2023-02-02]. http://arxiv.org/abs/1504.00702.
|
| [2] |
KOHL N, STONE P. Policy gradient reinforcement learning for fast quadrupedal locomotion[C]//Proceeding of the IEEE International Conference on Robotics and Automation. Piscataway: IEEE Press, 2004: 2619-2624.
|
| [3] |
LEE J, HWANGBO J, WELLHAUSEN L, et al. Learning quadrupedal locomotion over challenging terrain[J]. Science Robotics, 2020, 5(47): eabc5986. doi: 10.1126/scirobotics.abc5986
|
| [4] |
HWANGBO J, LEE J, DOSOVITSKIY A, et al. Learning agile and dynamic motor skills for legged robots[J]. Science Robotics, 2019, 4(26): eaau5872. doi: 10.1126/scirobotics.aau5872
|
| [5] |
HAARNOJA T, HA S, ZHOU A, et al. Learning to walk via deep reinforcement learning[EB/OL]. (2018-12-26)[2023-02-02]. http://arxiv.org/abs/1812.11103.
|
| [6] |
CZARNECKI W M, PASCANU R, OSINDERO S, et al. Distilling policy distillation[C]//Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics. Okinawa: PMLR, 2019: 1331-1340.
|
| [7] |
HONG Z W, NAGARAJAN P, MAEDA G. Periodic intra-ensemble knowledge distillation for reinforcement learning[C]//Proceedings of the Lecture Notes in Computer Science. Berlin: Springer, 2021: 87-103.
|
| [8] |
AMIK F R, TASIN A I, AHMED S, et al. Dynamic rectification knowledge distillation[EB/OL]. (2022-01-27)[2023-02-04]. http://arxiv.org/abs/2201.11319.
|
| [9] |
RUSU A A, COLMENAREJO S G, GULCEHRE C, et al. Policy distillation[EB/OL]. (2015-11-19)[2023-02-04]. http://arxiv.org/abs/1511.06295.
|
| [10] |
LAI K H, ZHA D C, LI Y N, et al. Dual policy distillation[EB/OL]. (2020-06-07)[2023-02-04]. http://arxiv.org/abs/2006.04061.
|
| [11] |
ZHAO C Y, HOSPEDALES T. Robust domain randomised reinforcement learning through peer-to-peer distillation[EB/OL]. (2020-12-09)[2023-02-04]. http://arxiv.org/abs/2012.04839.
|
| [12] |
徐平安, 刘全. 基于相似度约束的双策略蒸馏深度强化学习方法[J] 计算机科学, 2022, 11(12): 1-13.
XU P A, LIU Q. A dual-policy distillation deep reinforcement learning method based on similarity constraint[J]. Computer Science , 2022, 11(12): 1-13(in Chinese).
|
| [13] |
LEE Y H, LEE Y H, LEE H, et al. Development of a quadruped robot system with torque-controllable modular actuator unit[J]. IEEE Transactions on Industrial Electronics, 2021, 68(8): 7263-7273. doi: 10.1109/TIE.2020.3007084
|
| [14] |
BURDA Y, EDWARDS H, STORKEY A, et al. Exploration by random network distillation[EB/OL]. (2018-10-30)[2023-02-04]. http://arxiv.org/abs/1810.12894.
|
| [15] |
LIU I J, PENG J, SCHWING A G. Knowledge flow: Improve upon your teachers[EB/OL]. (2019-04-11)[2023-02-05]. http://arxiv.org/abs/1904.05878.
|
| [16] |
LIU D, HAN H Z, SHEN F Y. Dialogue policy optimization based on KL-GAN-A2C model[C]//Proceedings of the 16th International Computer Conference on Wavelet Active Media Technology and Information Processing. Piscataway: IEEE Press, 2019: 417-420.
|
| [17] |
LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[EB/OL]. (2019-07-15)[2023-02-05]. http://arxiv.org/abs/1509.02971.
|
| [18] |
YANG C Y, YUAN K, ZHU Q G, et al. Multi-expert learning of adaptive legged locomotion[J]. Science Robotics, 2020, 5(49): eabb2174. doi: 10.1126/scirobotics.abb2174
|
| [19] |
WILLIAMS R J. Simple statistical gradient-following algorithms for connectionist reinforcement learning[J]. Machine Learning, 1992, 8(3): 229-256.
|
| [20] |
HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor[EB/OL]. (2018-08-08)[2023-02-05]. http://arxiv.org/abs/1801.01290.
|
| [21] |
HAARNOJA T, TANG H R, ABBEEL P, et al. Reinforcement learning with deep energy-based policies[EB/OL]. (2017-07-21)[2023-02-05]. http://arxiv.org/abs/1702.08165.
|
| [22] |
HAARNOJA T, ZHOU A, HARTIKAINEN K, et al. Soft actor-critic algorithms and applications[EB/OL]. (2019-01-29)[2023-02-05]. http://arxiv.org/abs/1812.05905.
|
| [23] |
FUJIMOTO S, VAN HOOF H, MEGER D. Addressing function approximation error in actor-critic methods[EB/OL]. (2018-10-22)[2023-02-05]. http://arxiv.org/abs/1802.09477.
|
| [24] |
王君逸, 王志, 李华雄, 等. 基于自适应噪声的最大熵进化强化学习方法[J]. 自动化学报, 2023, 49(1): 54-66.
WANG J Y, WANG Z, LI H X, et al. Adaptive noise-based evolutionary reinforcement learning with maximum entropy[J]. Acta Automatica Sinica, 2023, 49(1): 54-66(in Chinese).
|
| [25] |
MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning[EB/OL]. (2016-06-16)[2023-02-05]. http://arxiv.org/abs/1602.01783.
|
| [26] |
SHI H J, ZHOU B, ZENG H S, et al. Reinforcement learning with evolutionary trajectory generator: A general approach for quadrupedal locomotion[J]. IEEE Robotics and Automation Letters, 2022, 7(2): 3085-3092. doi: 10.1109/LRA.2022.3145495
|
| [27] |
AGARWAL R, LIANG C, SCHUURMANS D, et al. Learning to generalize from sparse and underspecified rewards[EB/OL]. (2019-03-31)[2023-02-06]. http://arxiv.org/abs/1902.07198.
|
| [28] |
LI X S, ZHANG X H, NIU J K, et al. A stable walking strategy of quadruped robot based on ZMP in trotting gait[C]//Proceedings of the IEEE International Conference on Mechatronics and Automation. Piscataway: IEEE Press, 2022: 858-863.
|
| [29] |
HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network[EB/OL]. (2015-03-09)[2023-02-06]. http://arxiv.org/abs/1503.02531.
|
| [30] |
CUI J, KINGSBURY B, RAMABHADRAN B, et al. Knowledge distillation across ensembles of multilingual models for low-resource languages[C]//Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2017: 4825-4829.
|
| [31] |
ZHANG Y, XIANG T, HOSPEDALES T M, et al. Deep mutual learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 4320-4328.
|
| [32] |
WANG J Y, HU C X, ZHU Y. CPG-based hierarchical locomotion control for modular quadrupedal robots using deep reinforcement learning[J]. IEEE Robotics and Automation Letters, 2021, 6(4): 7193-7200. doi: 10.1109/LRA.2021.3092647
|
| [33] |
JOHNSON R W. An introduction to the bootstrap[J]. Teaching Statistics, 2001, 23(2): 49-54. doi: 10.1111/1467-9639.00050
|
| [34] |
GIRI R, RAO B D. Bootstrapped sparse Bayesian learning for sparse signal recovery[C]//Proceedings of the 48th Asilomar Conference on Signals, Systems and Computers. Piscataway: IEEE Press, 2014: 1657-1661.
|
| [35] |
ZHANG Z, YAN J Q, KONG X, et al. Efficient motion planning based on kinodynamic model for quadruped robots following persons in confined spaces[J]. IEEE/ASME Transactions on Mechatronics, 2021, 26(4): 1997-2006. doi: 10.1109/TMECH.2021.3083594
|
| [36] |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[C]//Proceedings of the 34th International Conference on Machine Learning. Sydney: PLMR, 2017: 3379-3387.
|
Figures(12) / Tables(1)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@cqjj8.com
Supported by:
Beijing Renhe Information Technology Co., Ltd.





 DownLoad:
DownLoad: