| Citation: | WANG Y G,YAO S Z,TAN H B. Residual SDE-Net for uncertainty estimates of deep neural networks[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(8):1991-2000 (in Chinese) doi: 10.13700/j.bh.1001-5965.2021.0604

|
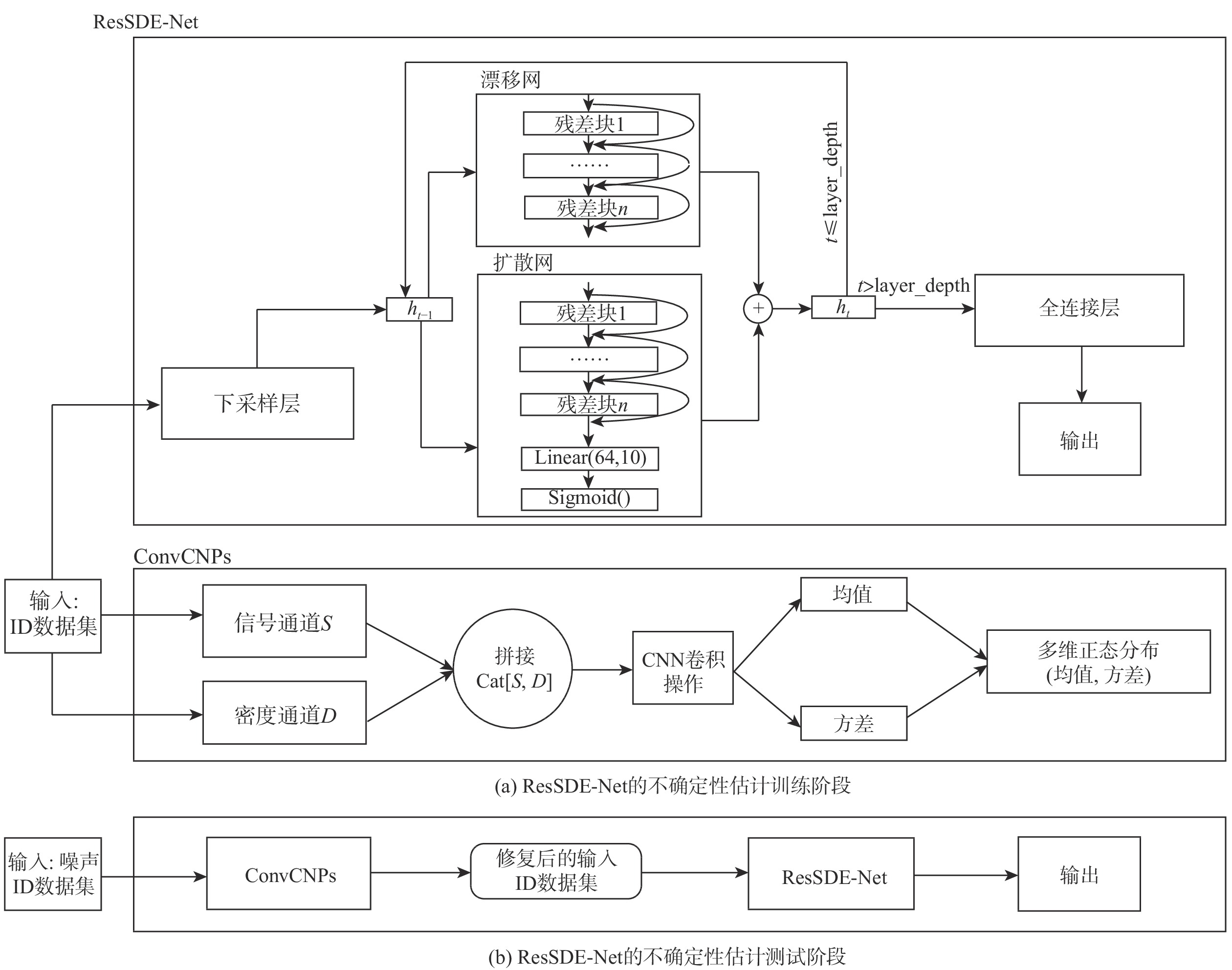
The neural stochastic differential equation model (SDE-Net) can quantify epistemic uncertainties of deep neural networks (DNNs) from the perspective of a dynamical system. However, SDE-Net faces two problems. Firstly, when dealing with largescale datasets, performance degrades as network layers increase. Secondly, SDE-Net has poor performance in dealing with aleatoric uncertainties caused by in-distribution data with noise or a high missing rate. In order to achieve consistent stability and higher performance, this paper first designs a residual SDE-Net (ResSDE-Net) model, which enhances the residual blocks in residual networks (ResNets). next, convolutional conditional neural processes (ConvCNPs) with translation equivariance are introduced to complete in-distribution data that has noise or a high rate of missing data in order to enhance the ResSDE-Net's processing ability for such datasets. The experimental results demonstrate that the ResSDE-Net performs consistently and predictably when dealing with in-distribution and out-of-distribution data. Additionally, the model still achieves an average accuracy of 89.89%, 65.22%, and 93.02% on the real-world SVHN datasets and the MNIST, CIFAR10, and CIFAR10 datasets, where 70% of the pixels are lost, respectively.

| [1] |
KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[C]//26th Advances in Neural Information Processing Systems. La Jolla: MIT press, 2012: 1097-1105.
|
| [2] |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778.
|
| [3] |
张钹, 朱军, 苏航. 迈向第三代人工智能[J]. 中国科学:信息科学, 2020, 50(9): 1281-1302. doi: 10.1360/SSI-2020-0204
ZHANG B, ZHU J, SU H. Toward the third generation of artificial intelligence[J]. Scientia Sinica (Informationis), 2020, 50(9): 1281-1302(in Chinese). doi: 10.1360/SSI-2020-0204
|
| [4] |
GUO C, PLEISS G, SUN Y, et al. On calibration of modern neural networks[C]//Proceedings of the 34th International Conference on Machine Learning. New York: ACM, 2017: 1321-1330.
|
| [5] |
CHEN R T Q, RUBANOVA Y, BETTENCOURT J, et al. Neural ordinary differential equations[C]//Proceedings of the 32nd International Conference on Neural Information Processing Systems. La Jolla: MIT Press, 2018: 6572–6583.
|
| [6] |
KONG L K, SUN J M, ZHANG C. SDE-Net: Equipping deep neural networks with uncertainty estimates[C]//Proceedings of the 37th International Conference on Machine Learning. New York: ACM, 2020: 5405-5415.
|
| [7] |
ØKSENDAL B. Stochastic differential equations[M]. Berlin: Springer, 2003: 65-84.
|
| [8] |
BASS R F. Stochastic processes[M]. New York: Cambridge University Press, 2011: 6.
|
| [9] |
JEANBLANC M, YOR M, CHESNEY M. Continuous-path random processes: Mathematical prerequisites[M]. Mathematical Methods for Financial Markets. Berlin: Springer, 2009: 3-78.
|
| [10] |
HE K M, ZHANG X Y, REN S Q, et al. Identity mappings in deep residual networks[C]//European Conference on Computer Vision. Berlin: Springer, 2016: 630-645.
|
| [11] |
GORDON J, BRUINSMA W P, FOONG A Y K, et al. Convolutional conditional neural processes[C]//8th International Conference on Learning Representations. Addis Ababa: OpenReview.net, 2020.
|
| [12] |
REZENDE D, MOHAMED S. Variational Inference with Normalizing Flows[C]//Proceedings of the 32nd International Conference on Machine Learning. New York: ACM, 2015: 1530–1538.
|
| [13] |
RAISSI M, KARNIADAKIS G E. Hidden physics models: Machine learning of nonlinear partial differential equations[J]. Journal of Computational Physics, 2018, 357: 125-141. doi: 10.1016/j.jcp.2017.11.039
|
| [14] |
HE K M, SUN J. Convolutional neural networks at constrained time cost[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2015: 5353-5360.
|
| [15] |
EMIN O, XAQ P. Skip connections eliminate singularities[C] //International Conference on Learning Representations. Vancouver: OpenReview.net, 2018.
|
| [16] |
LALLEY S P. Stochastic differential equations[D]. Chicago: University of Chicago, 2016: 1-11.
|
| [17] |
朱军, 胡文波. 贝叶斯机器学习前沿进展综述[J]. 计算机研究与发展, 2015, 52(1): 16-26. doi: 10.7544/issn1000-1239.2015.20140107
ZHU J, HU W B. Recent advances in Bayesian machine learning[J]. Journal of Computer Research and Development, 2015, 52(1): 16-26(in Chinese). doi: 10.7544/issn1000-1239.2015.20140107
|
| [18] |
BLUNDELL C, CORNEBISE J, KAVUKCUOGLU K, et al. Weight uncertainty in neural network[C]//Proceedings of the 32nd International Conference on Machine Learning. New York: ACM, 2015: 1613-1622.
|
| [19] |
MALININ A, GALES M J F. Predictive uncertainty estimation via prior networks[C]//Advances in Neural Information Processing System. La Jolla: MIT Press, 2018: 7047-7058.
|
| [20] |
GAL Y, GHAHRAMANI Z. Dropout as a Bayesian approximation: representing model uncertainty in deep learning[C]//Proceedings of the 33rd International Conference on International Conference on Machine Learning. New York: ACM, 2016: 1050-1059.
|
| [21] |
HENDRYCKS D, GIMPEL K. A baseline for detecting misclassified and out-of-distribution examples in neural networks[C]//International Conference on Learning Representations, arxiv: OpenReview.net, 2016.
|
| [22] |
LI C, CHEN C, CARLSON D, et al. Preconditioned stochastic gradient langevin dynamics for deep neural networks[C]//AAAI Conference on Artificial Intelligence. Palo Alto: AAAI, 2016: 1788-1794.
|
| [23] |
LAKSHMINARAYANAN B, PRITZEL A, BLUNDELL C. Simple and scalable predictive uncertainty estimation using deep ensemble[C]//Advances in Neural Information Processing System. La Jolla: MIT Press, 2017: 6402-6413.
|

Figures(5) / Tables(3)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@cqjj8.com
Supported by:
Beijing Renhe Information Technology Co., Ltd.





 DownLoad:
DownLoad: