| Citation: | BIE T,ZHU X Q,FU Y,et al. Safety priority path planning method based on Safe-PPO algorithm[J]. Journal of Beijing University of Aeronautics and Astronautics,2023,49(8):2108-2118 (in Chinese) doi: 10.13700/j.bh.1001-5965.2021.0580

|
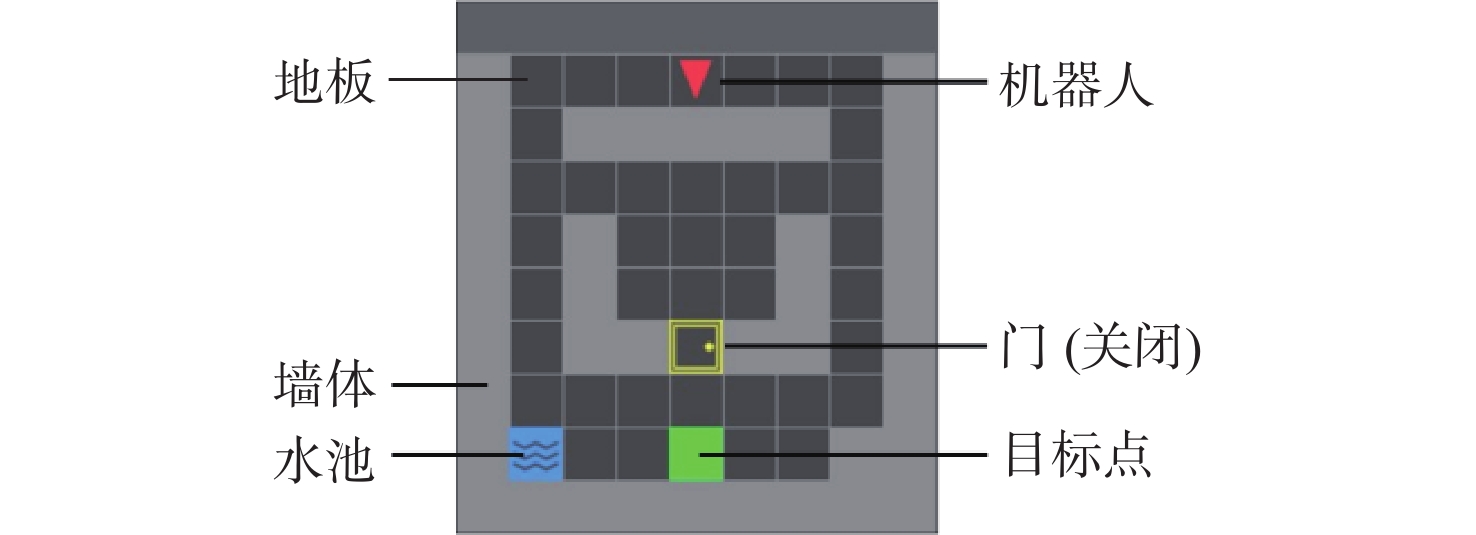
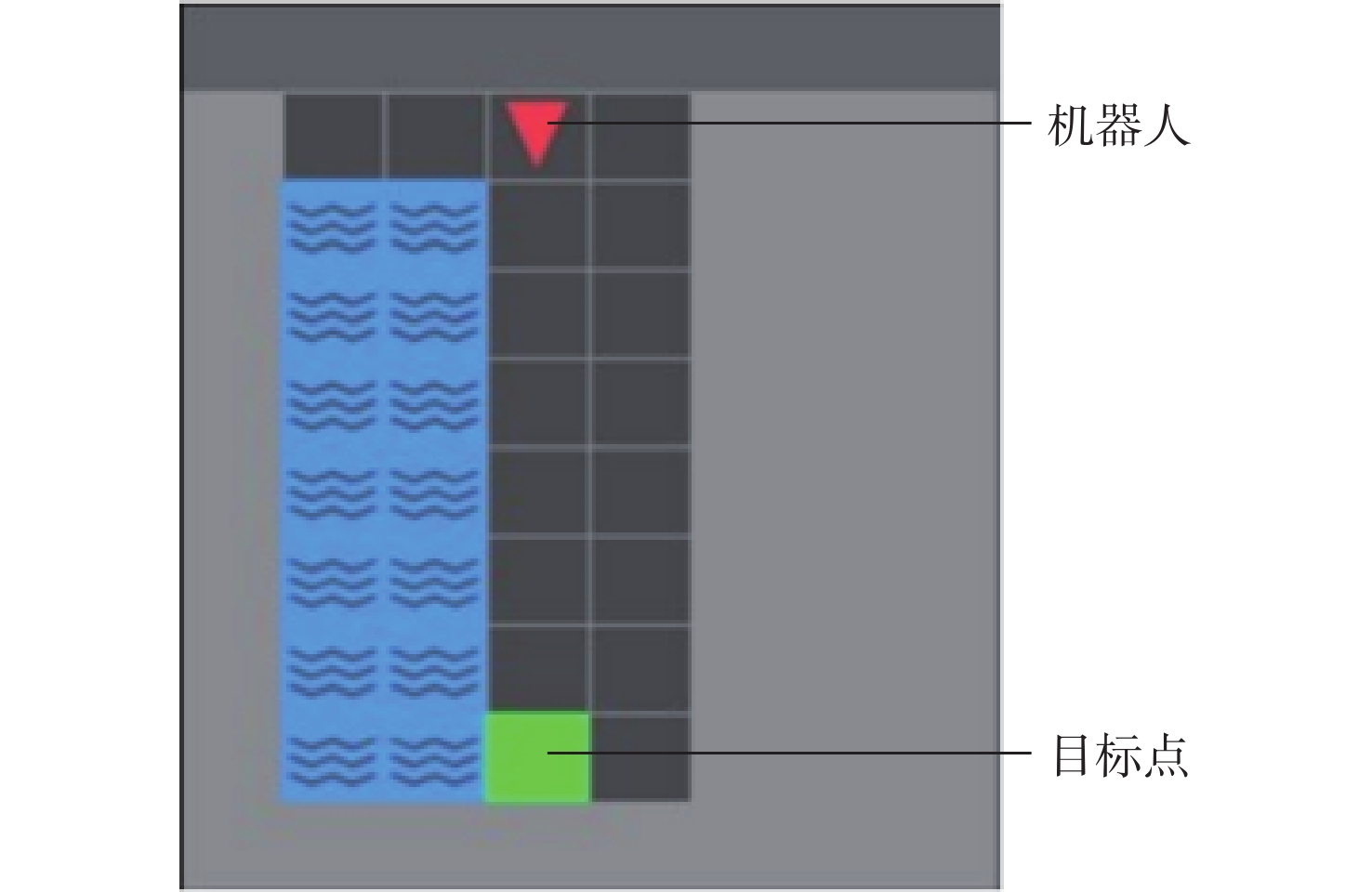
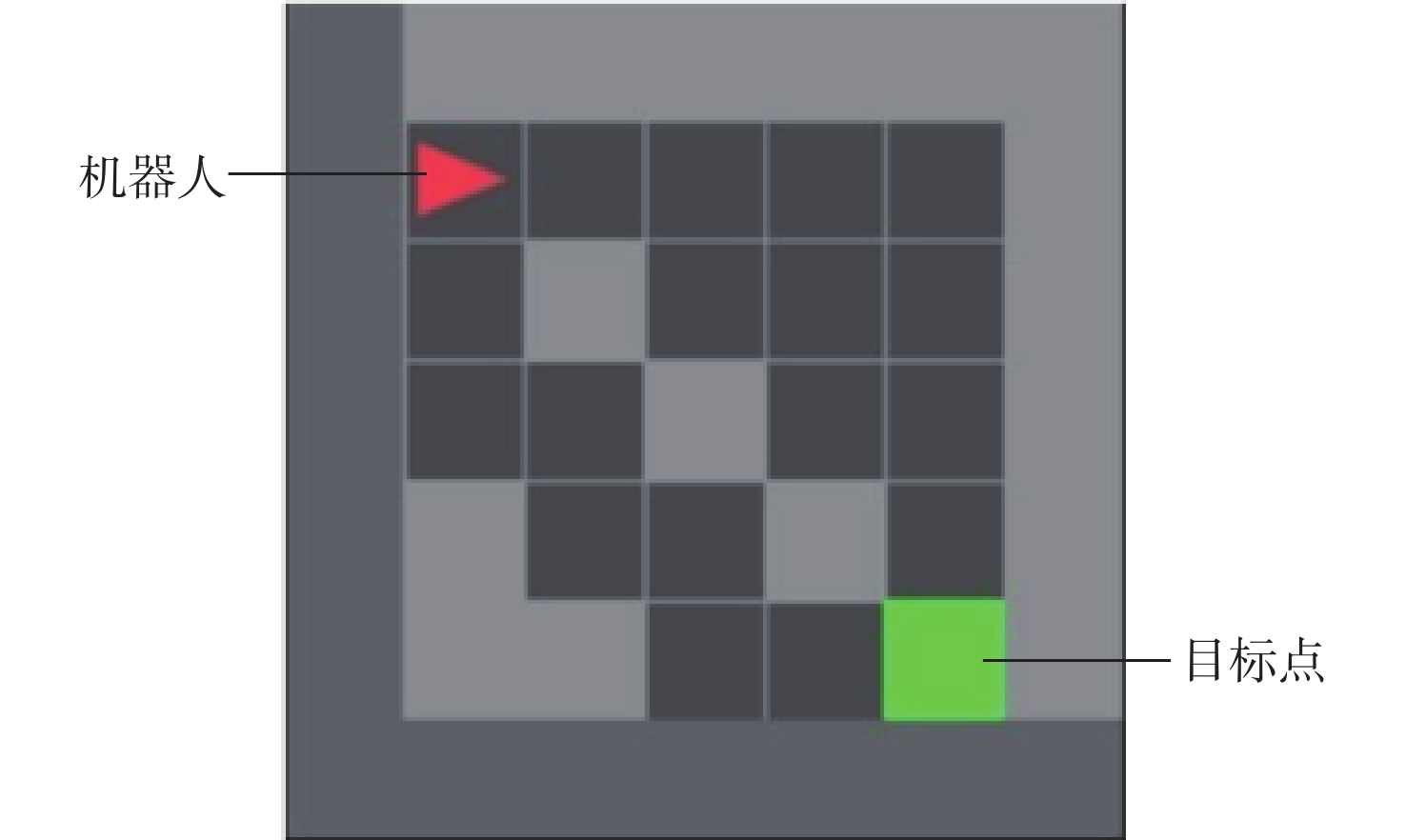
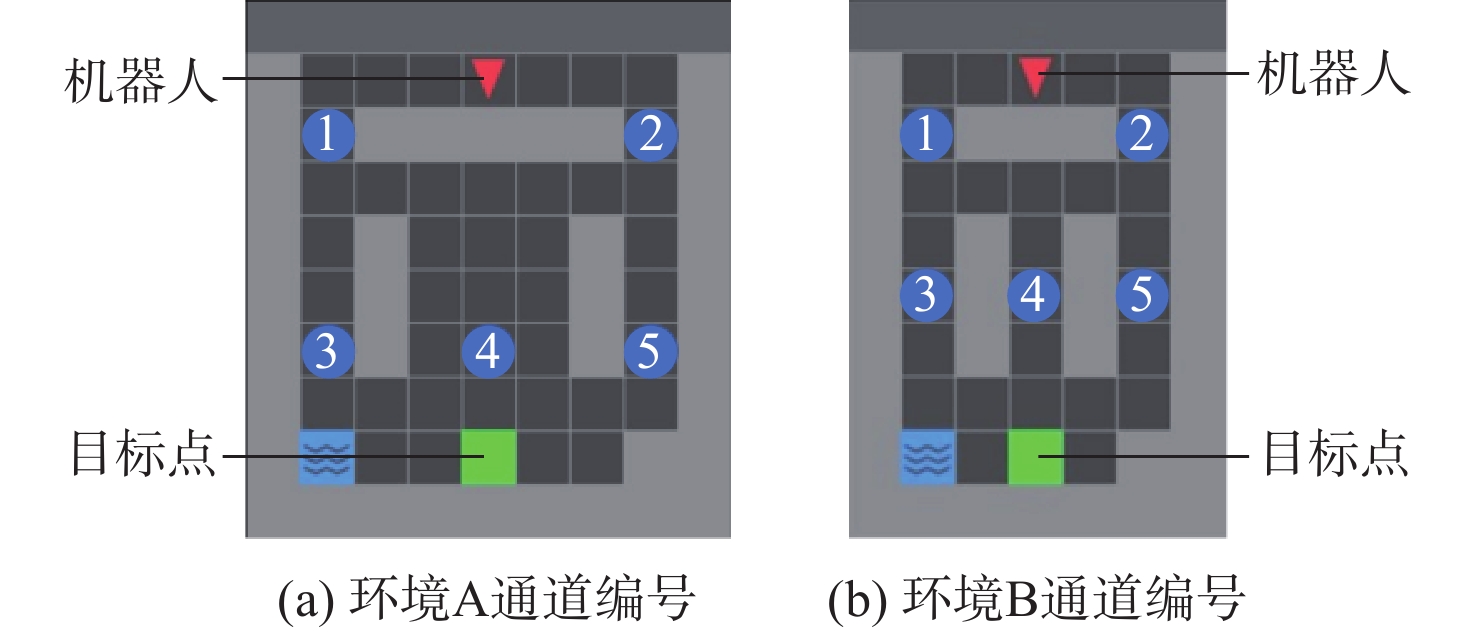
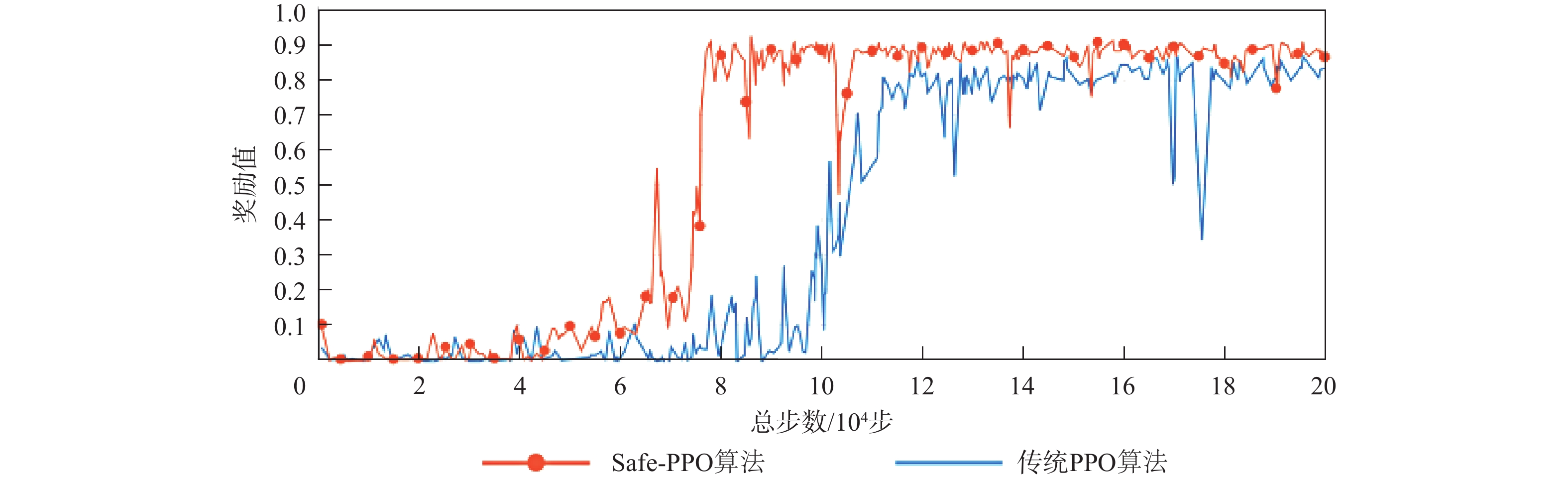
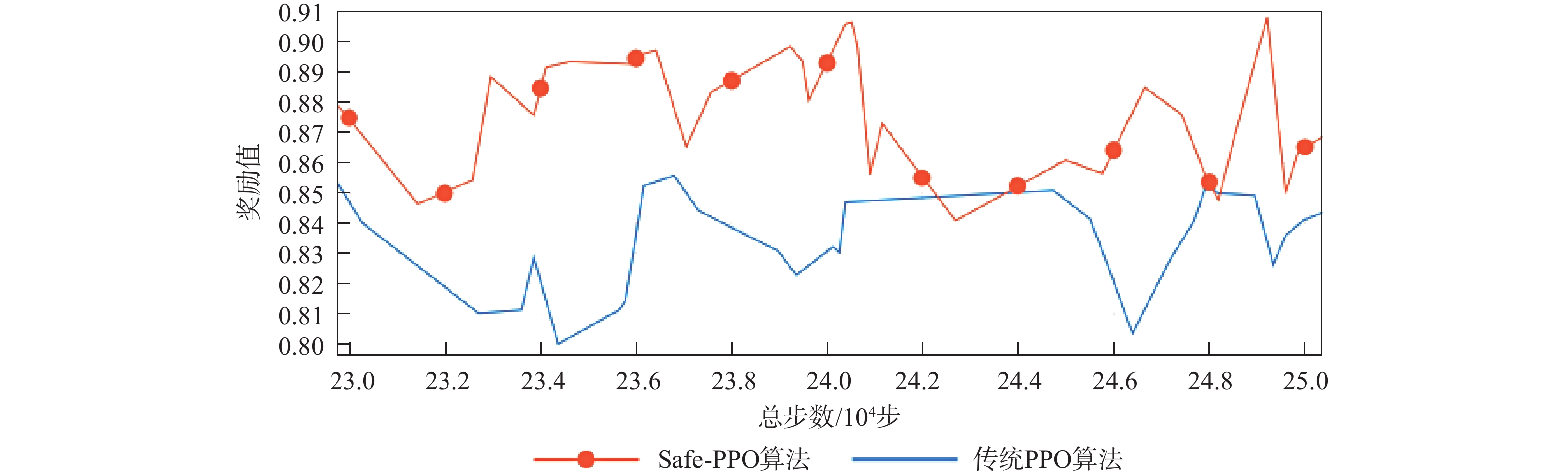
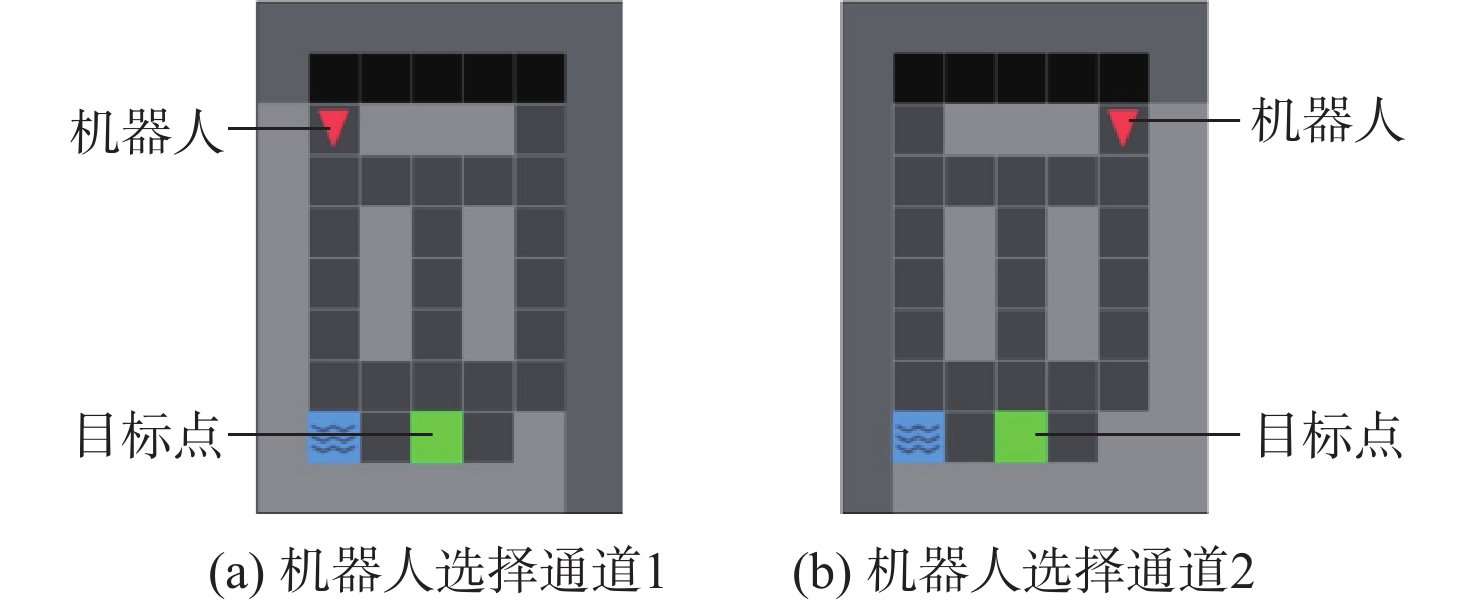
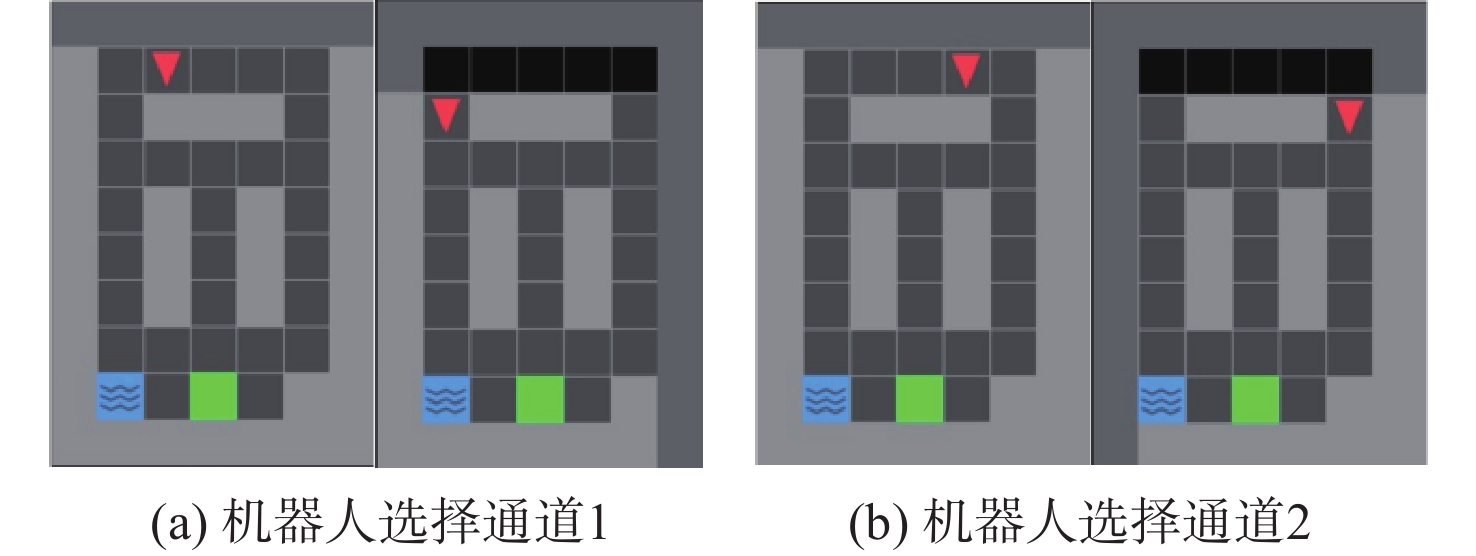
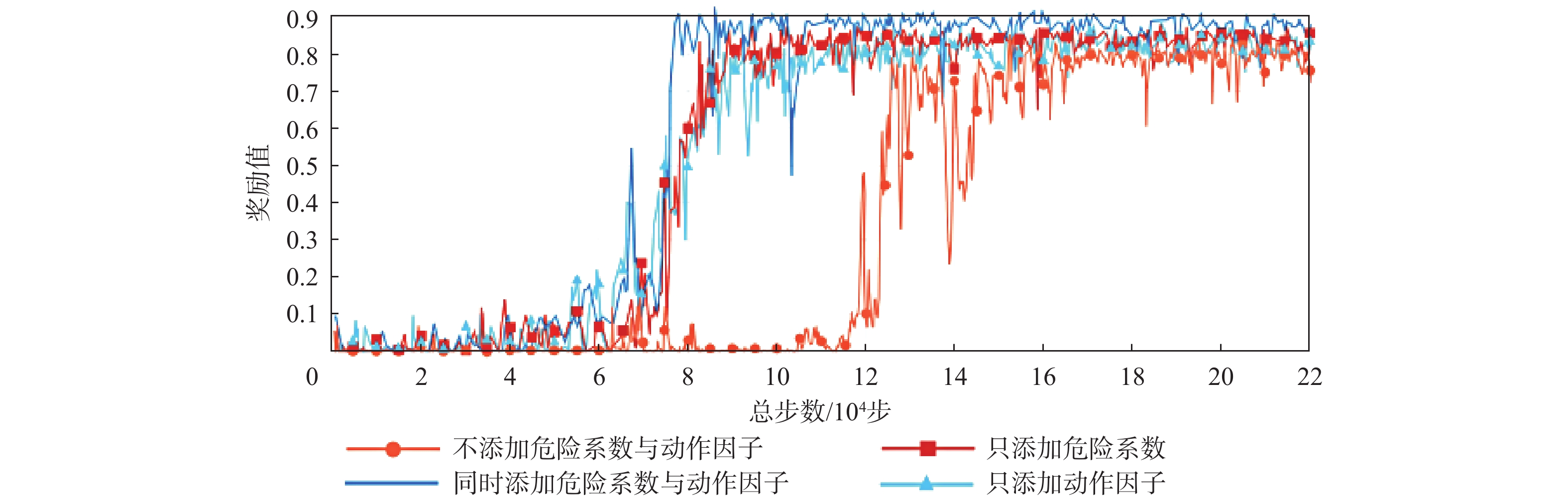
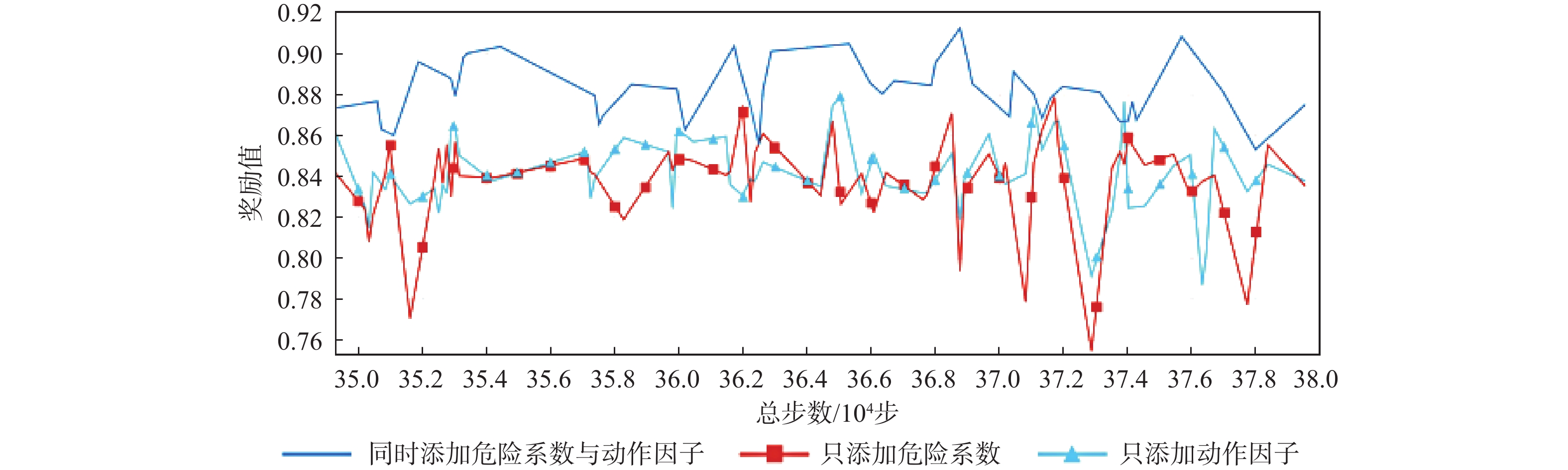
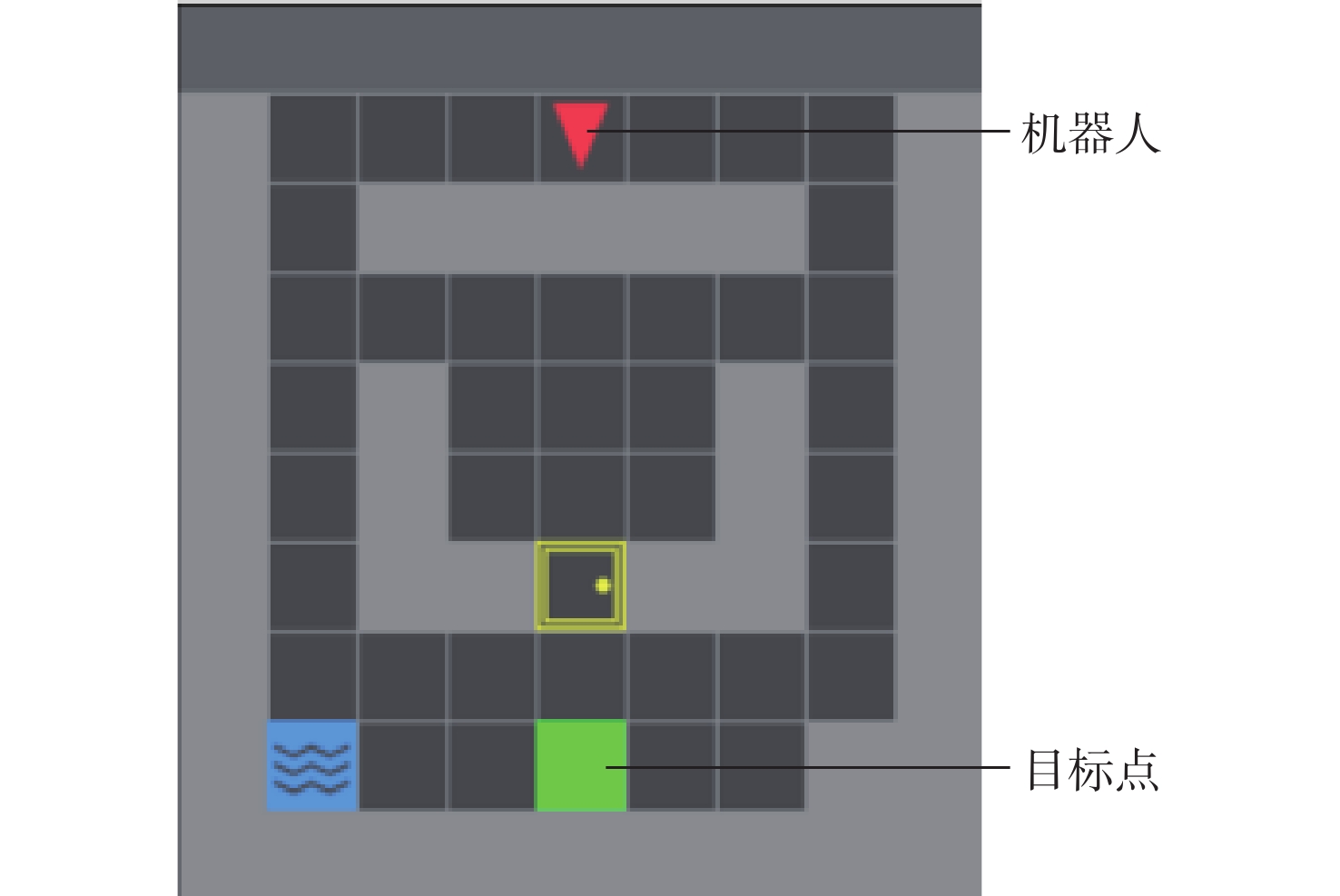
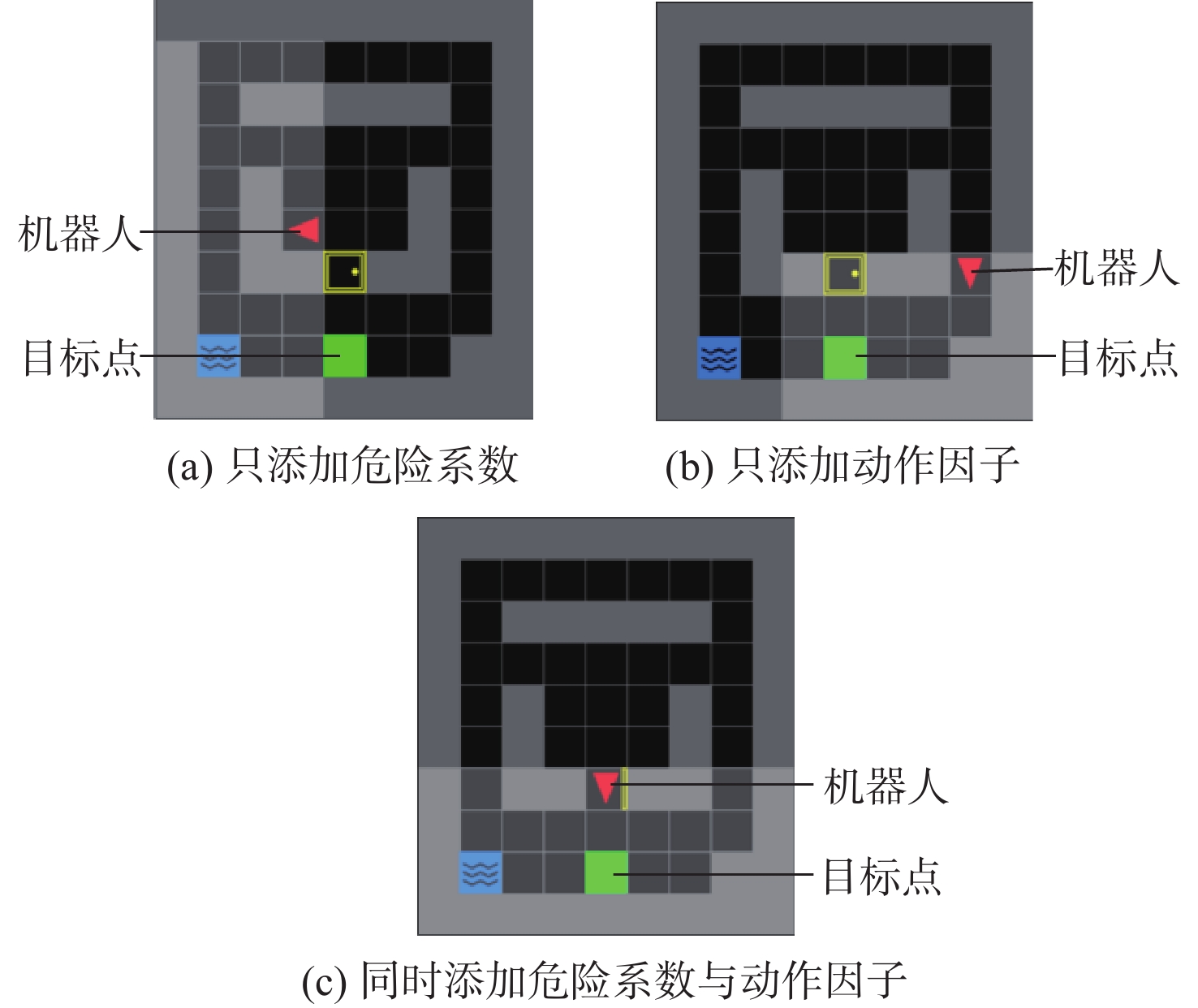
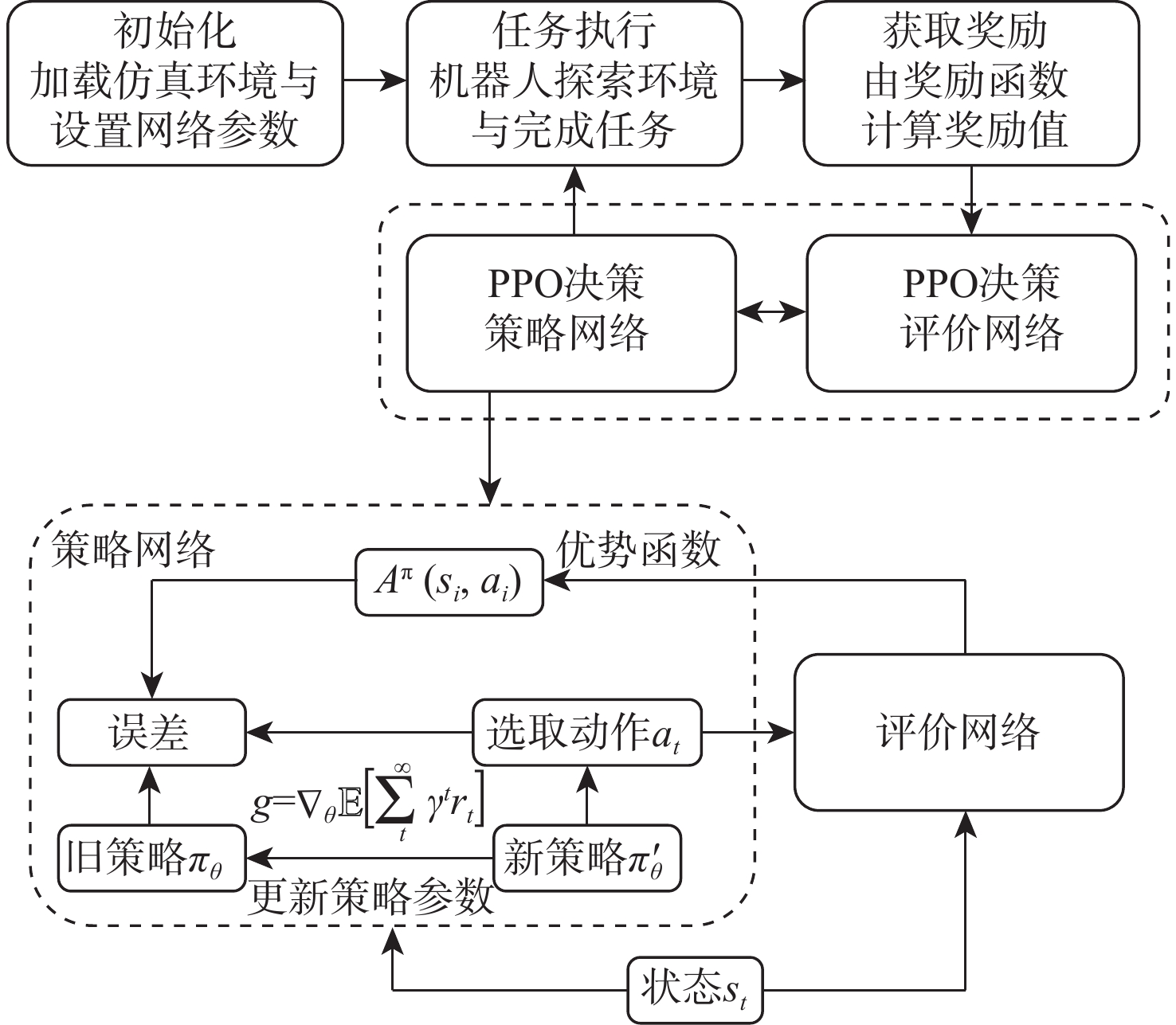
The existing path planning algorithms seldom consider the problem of security, and the traditional proximal policy optimization(PPO) algorithm has a variance adaptability problem. To solve these problems, the Safe-PPO algorithm combining evolutionary strategy and safety reward function was proposed. The algorithm is safety-oriented for path planning. CMA-ES was used to improve the PPO algorithm. The hazard coefficient and movement coefficient were introduced to evaluate the safety of the path. Used a grid map for simulation experiments, and compared the traditional PPO algorithm with the Safe-PPO algorithm; The hexapod robot was used to carry out the physical experiment in the constructed scene. The simulation results show that the Safe-PPO algorithm is reasonable and feasible in safety-oriented path planning. When compared to the conventional PPO algorithm, the Safe-PPO algorithm increased the rate of convergence during training by 18% and the incentive received by 5.3%. Using the algorithm that combined the Hazard coefficient and movement coefficient during testing enabled the robot to learn to choose the safer path rather than the fastest one. The outcomes of the physical testing demonstrated that the robot could select a more secure route to the objective in the created setting.

| [1] |
魏彤, 龙琛. 基于改进遗传算法的移动机器人路径规划[J]. 北京亚洲成人在线一二三四五六区学报, 2020, 46(4): 703-711. doi: 10.13700/j.bh.1001-5965.2019.0298
WEI T, LONG C. Path planning for mobile robot based on improved genetic algorithm[J]. Journal of Beijing University of Aeronautics and Astronautics, 2020, 46(4): 703-711(in Chinese). doi: 10.13700/j.bh.1001-5965.2019.0298
|
| [2] |
XU Y R, LIU R. Path planning for mobile articulated robots based on the improved A* algorithm[J]. International Journal of Advanced Robotic Systems, 2017, 14(4): 1-10.
|
| [3] |
MAJUMDER S, PRASAD M S. Three dimensional D* algorithm for incremental path planning in uncooperative environment[C]//2016 3rd International Conference on Signal Processing and Integrated Networks. Piscataway: IEEE Press, 2016: 431-435.
|
| [4] |
MASHAYEKHI R, IDRIS M Y I, ANISI M H, et al. Hybrid RRT: A semi-dual-tree RRT-based motion planner[J]. IEEE Access, 2020, 8: 18658-18668. doi: 10.1109/ACCESS.2020.2968471
|
| [5] |
LIU J H, YANG J G, LIU H P, et al. An improved ant colony algorithm for robot path planning[J]. Soft Computing, 2017, 21(19): 5829-5839. doi: 10.1007/s00500-016-2161-7
|
| [6] |
董豪, 杨静, 李少波, 等. 基于深度强化学习的机器人运动控制研究进展[J]. 控制与决策, 2022, 37(2): 278-292.
DONG H, YANG J, LI S B, et al. Research progress of robot motion control based on deep reinforcement learning[J]. Control and Decision, 2022, 37(2): 278-292(in Chinese).
|
| [7] |
VOLODYMYR M, KORAY K, DAVID S, et al. Playing atari with deep reinforcement learning[EB/OL]. (2013-12-19)[2021-09-01].
|
| [8] |
GU S, TIMOTHY L, ILYA S, et al. Continuous deep Q-learning with model-based acceleration[C]//33rd International Conference on Machine Learning. New York: International Machine Learning Society, 2016: 2829-2838.
|
| [9] |
JOHN S, SERGEY L, PHILIPP M, et al. Trust region policy optimization[C]//32th International Conference on Machine Learning. Lille: International Machine Learning Society, 2015: 1889-1897.
|
| [10] |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. (2017-08-28)[2020-09-01].
|
| [11] |
MNIH V, ADRI`AP B, MEHDI M, et al. Asynchronous methods for deep reinforcement learning[C]//33rd International Conference on Machine Learning. New York: International Machine Learning Society, 2016: 1928-1937.
|
| [12] |
多南讯, 吕强, 林辉灿, 等. 迈进高维连续空间: 深度强化学习在机器人领域中的应用[J]. 机器人, 2019, 41(2): 276-288.
DUO N X, LV Q, LIN H C, et al. Step into high-dimensional and continuous action space: A survey on applications of deep reinforcement learning to robotics[J]. Robot, 2019, 41(2): 276-288(in Chinese).
|
| [13] |
沈鹏. 自主车辆复杂环境下安全导航方法研究[D]. 淄博: 山东理工大学, 2019: 36-49.
SHEN P. Research on safe navigation method of autonomous vehicles in complex environment[D]. Zibo: Shandong University of Technology, 2019: 36-49(in Chinese).
|
| [14] |
邵旭阳. 家庭环境下面向高效与安全导航的二维物品语义地图构建[D]. 济南: 山东大学, 2021: 65-81.
SHAO X Y. Construction of two-dimensional object semantic map for efficient and safe navigation in home environment[D]. Jinan: Shandong University, 2021: 65-81(in Chinese).
|
| [15] |
ESHGHI M, SCHMIDTKE H R. An approach for safer navigation under severe hurricane damage[J]. Journal of Reliable Intelligent Environments, 2018, 4(3): 161-185. doi: 10.1007/s40860-018-0066-1
|
| [16] |
HEESS N, TB D, SRIRAM S, et al. Emergence of locomotion behaviours in rich environments[EB/OL]. (2017-7-10)[2021-9-1].
|
| [17] |
HAN S, ZHOU W B, LÜ S, et al. Regularly updated deterministic policy gradient algorithm[EB/OL]. (2020-7-1)[2021-9-1].
|
| [18] |
WU J T, LI H Y. Deep ensemble reinforcement learning with multiple deep deterministic policy gradient algorithm[J]. Mathematical Problems in Engineering, 2020, 2020: 1-12.
|
| [19] |
HANSEN N. The CMA evolution strategy: A comparing review[C]//Towards a New Evolutionary Computation. Berlin: Springer, 2007: 75-102.
|
| [20] |
LOSHCHILOV I, GLASMACHERS T, BEYER H G. Large scale black-box optimization by limited-memory matrix adaptation[J]. IEEE Transactions on Evolutionary Computation, 2019, 23(2): 353-358. doi: 10.1109/TEVC.2018.2855049
|
| [21] |
DE BOER P T, KROESE D P, MANNOR S, et al. A tutorial on the cross-entropy method[J]. Annals of Operations Research, 2005, 134(1): 19-67. doi: 10.1007/s10479-005-5724-z
|
| [22] |
LARRAÑAGA P, LOZANO J A. Estimation of distribution algorithms: A new tool for evolutionary computation[M]. Boston: Kluwer Academic Publishers, 2002.
|
| [23] |
HANSEN N. The CMA evolution strategy: A tutorial[EB/OL]. (2016-4-4)[2021-9-1].
|
| [24] |
PENG X B, KUMAR A, ZHANG G, et al. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning[J/OL]. Machine Learning, 2019, (2019-10-7)[2021-9-1]. DOI: 10.48550/arXiv.1910.00177.
|
| [25] |
JOHN S, PHILIPP M, SERGEY L, et al. High-dimensional continuous control using generalized advantage estimation[J/OL]. Computer Science, 2015, (2018-10-20)[2021-9-1]. DOI: 10.48550/arXiv.1506.02438.
|
Figures(23) / Tables(1)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@cqjj8.com
Supported by:
Beijing Renhe Information Technology Co., Ltd.





 DownLoad:
DownLoad: