| Citation: | LIN Keyu, JIANG Hongxu, ZHANG Yonghua, et al. Design and FPGA implementation of fast convolution algorithm based on 3D-Winograd[J]. Journal of Beijing University of Aeronautics and Astronautics, 2021, 47(9): 1900-1907. doi: 10.13700/j.bh.1001-5965.2020.0310(in Chinese)

|
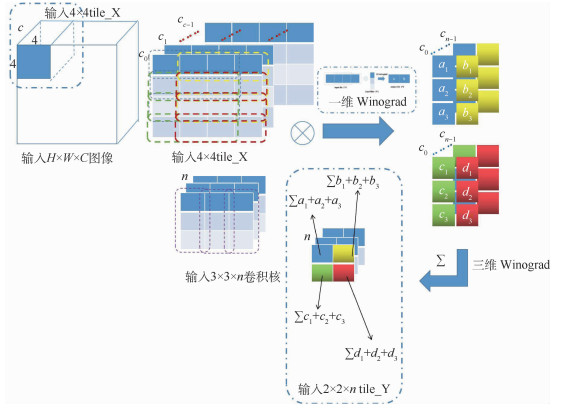
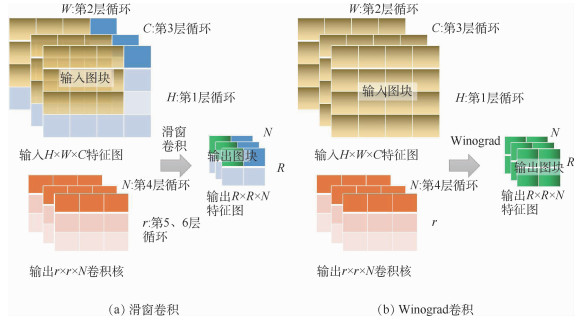
In recent years, Convolutional Neural Networks (CNNs) have been widely adopted by computer vision tasks. Due to the high performance, energy efficiency, and reconfigurability of FPGA, it has been considered as the most promising CNN hardware accelerator. However, the existing FPGA solutions based on the traditional Winograd method are usually limited by FPGA computing power and storage resources, and there is room for improvement in performance of 3D convolution operations. This paper first studied the one-dimensional expansion process of the Winograd algorithm suitable for three-dimensional operations; then, improved the performance of CNN on FPGA by increasing the one-time input feature map and the dimensional size of the convolution block, low-bit quantization weight and input data. The optimization ideas include four parts: the method of using shift instead of partial division, the division of tiles, the expansion of two-dimensional to three-dimensional, and low-bit quantization. Compared with the traditional two-dimensional Winograd algorithm, the number of clock cycles of each convolutional layer of the optimized algorithm is reduced by about 7 times, which is about 7 times less for each convolutional layer than the traditional sliding window convolution algorithm. Through the research, it is proved that the 3D-Winograd algorithm based on one-dimensional expansion can greatly reduce the computational complexity and improve the performance of running CNN on FPGA.

| [1] |
ZHANG X F, WANG J S, ZHU C, et al. AccDNN: An IP-based DNN generator for FPGAs[C]//2018 IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM). Piscataway: IEEE Press, 2018: 210.
|
| [2] |
GUAN Y J, LIANG H, XU N Y, et al. FP-DNN: An automated framework for mapping deep neural networks onto FPGAs with RTL-HLS hybrid templates[C]//2017 IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines(FCCM). Piscataway: IEEE Press, 2017: 152-159.
|
| [3] |
GEORGE J K, NEJADRIAHI H, SORGER V J. Towards on-chip optical FFTs for convolutional neural networks[C]//2017 IEEE International Conference on Rebooting Computing(ICRC). Piscataway: IEEE Press, 2017: 1-4.
|
| [4] |
ORDÓÑEZ Á, ARGVELLO F, HERAS D B. GPU accelerated FFT-based registration of hyperspectral scenes[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2017, 10(11): 4869-4878. doi: 10.1109/JSTARS.2017.2734052
|
| [5] |
SUITA S, NISHIMURA T, TOKURA H, et al. Efficient cuDNN-compatible convolution-pooling on the GPU[C]//International Conference on Parallel Processing and Applied Mathematics. Berlin: Springer, 2019: 46-58.
|
| [6] |
ZHANG C, PRASANNA V. Frequency domain acceleration of convolutional neural networks on CPU-FPGA shared memory system[C]//FPGA'17: Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2017: 35-44.
|
| [7] |
CONG J, XIAO B J. Minimizing computation in convolutional neural networks[M]//Artificial Neural Networks and Machine Learning-ICANN 2014. Berlin: Springer, 2014: 281-290.
|
| [8] |
SUDA N, CHANDRA V, DASIKA G, et al. Throughput-optimized OpenCL-based FPGA accelerator for large-scale convolutional neural networks[C]//FPGA'16: Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2016: 16-25.
|
| [9] |
ZHANG C, SUN G Y, FANG Z M, et al. Caffeine: Toward uniformed representation and acceleration for deep convolutional neural networks[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2019, 38(11): 2072-2085. doi: 10.1109/TCAD.2017.2785257
|
| [10] |
LAVIN A, GRAY S. Fast algorithms for convolutional neural networks[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Piscataway: IEEE Press, 2016: 4013-4021.
|
| [11] |
ZHANG C, LI P, SUN G Y, et al. Optimizing FPGA-based accelerator design for deep convolutional neural networks[C]//FPGA'15: Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2015: 161-170.
|
| [12] |
QIU J T, WANG J, YAO S, et al. Going deeper with embedded FPGA platform for convolutional neural network[C]//FPGA'16: Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2016: 26-35.
|
| [13] |
YU J C, GE G J, HU Y M, et al. Instruction driven cross-layer CNN accelerator for fast detection on FPGA[J]. ACM Transactions on Reconfigurable Technology and Systems, 2018, 11(3): 1-23.
|
| [14] |
AHMAD A, PASHA M A. Towards design space exploration and optimization of fast algorithms for convolutional neural networks (CNNs) on FPGAs[C]//2019 Design, Automation & Test in Europe Conference & Exhibition (DATE). Piscataway: IEEE Press, 2019: 1106-1111.
|
| [15] |
LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. doi: 10.1109/5.726791
|
| [16] |
LIANG Y, LU L Q, XIAO Q C, et al. Evaluating fast algorithms for convolutional neural networks on FPGAs[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2020, 39(4): 857-870. doi: 10.1109/TCAD.2019.2897701
|
| [17] |
LU L Q, LIANG Y. SpWA: An efficient sparse Winograd convolutional neural networks accelerator on FPGAs[C]//2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC). Piscataway: IEEE Press, 2018: 1-6.
|
| [18] |
ZHAO Y L, WANG D H, WANG L O. Convolution accelerator designs using fast algorithms[J]. Algorithms, 2019, 12(5): 112. doi: 10.3390/a12050112
|
| [19] |
REDMON J, FARHADI A. YOLO9000: Better, faster, stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Piscataway: IEEE Press, 2017: 6517-6525.
|
Figures(4) / Tables(5)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@cqjj8.com
Supported by:
Beijing Renhe Information Technology Co., Ltd.





 DownLoad:
DownLoad: