



An object detection algorithm based on feature enhancement and adaptive threshold non-maximum suppression
-
摘要:
为进一步解决目标漏检和重复检测等问题,提升目标检测的性能,提出一种基于特征增强与自适应阈值的非极大值抑制(NMS)目标检测算法。将注意力引导的多尺度上下文模块(AMCM)用于检测器颈部,在利用空洞卷积提升特征语义信息的基础上,通过注意力捕获跨通道位置信息,增强网络的特征表达能力;通过基于目标密度的自适应阈值NMS(ADT-NMS),针对不同场景的实例应用动态抑制阈值,降低目标的误检率。所提算法在PASCAL VOC数据集上误检率为13.7%,相比基准算法YOLOv4降低了1%,检测精度、召回率分别达到83.7%、96.6%,分别提高了1.7%、0.9%;在KITTI数据集上误检率为22.1%,相比基准算法降低了1.3%,检测精度、召回率分别达到83.6%、91.8%,分别提高了1.8%、2.3%。实验结果表明:所提算法较好地解决了目标漏检和重复检测问题。
Abstract:To further solve the problems of object omission and repeated detection and improve the accuracy of object detection, this paper proposes an object detection algorithm based on feature enhancement and adaptive threshold non-maximum suppression(NMS). The attention-guided multi-scale context module(AMCM) is applied to the neck of the detector. Based on improving the semantic information of features by dilated convolution, the cross-channel location information is captured by the attention mechanism, so as to enhance the feature expression ability of the network. The dynamic suppression threshold is adaptively applied to instances of the scenes through the adaptive density threshold of NMS(ADT-NMS), which lowers the false detection rate for objects. In comparison to the baseline algorithm YOLOv4, the suggested approach’s false detection rate on the PASCAL VOC dataset is 13.7%, a 1% decrease. The recall rate and detection accuracy increase by 0.9% and 1.7%, respectively, to 96.6% and 83.7%. The false detection rate of the proposed algorithm on the KITTI dataset achieves 22.1%, reduced by 1.3%. The detection accuracy and recall rate achieved 83.6% and 91.8%, improved by 1.8% and 2.3%, respectively. The experimental results show that the algorithm can better solve the problems of object omission and repeated detection.
-

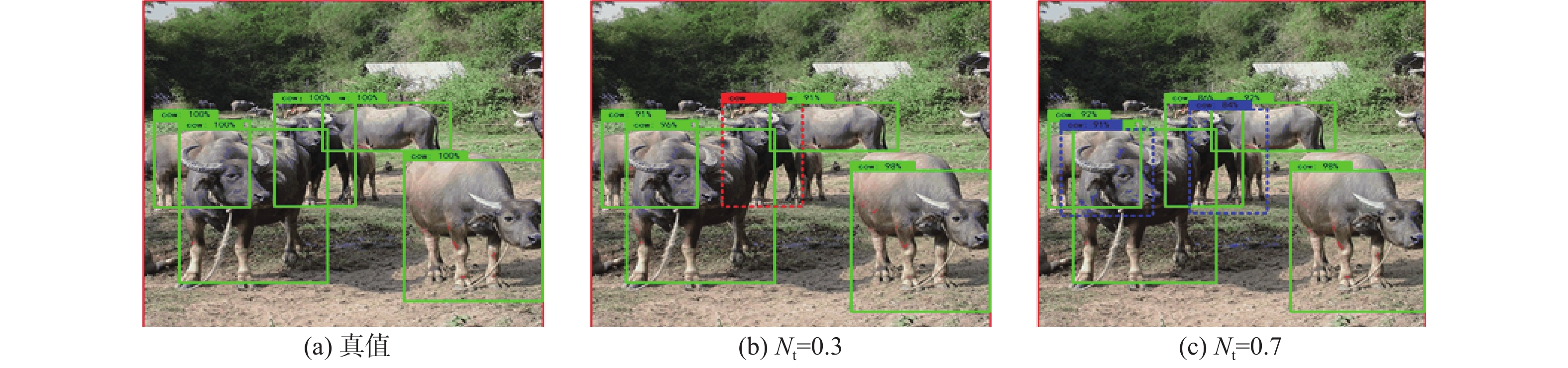
图 1 DIoU-NMS 在不同阈值下的检测结果
Figure 1. Detection results of DIoU-NMS under different thresholds
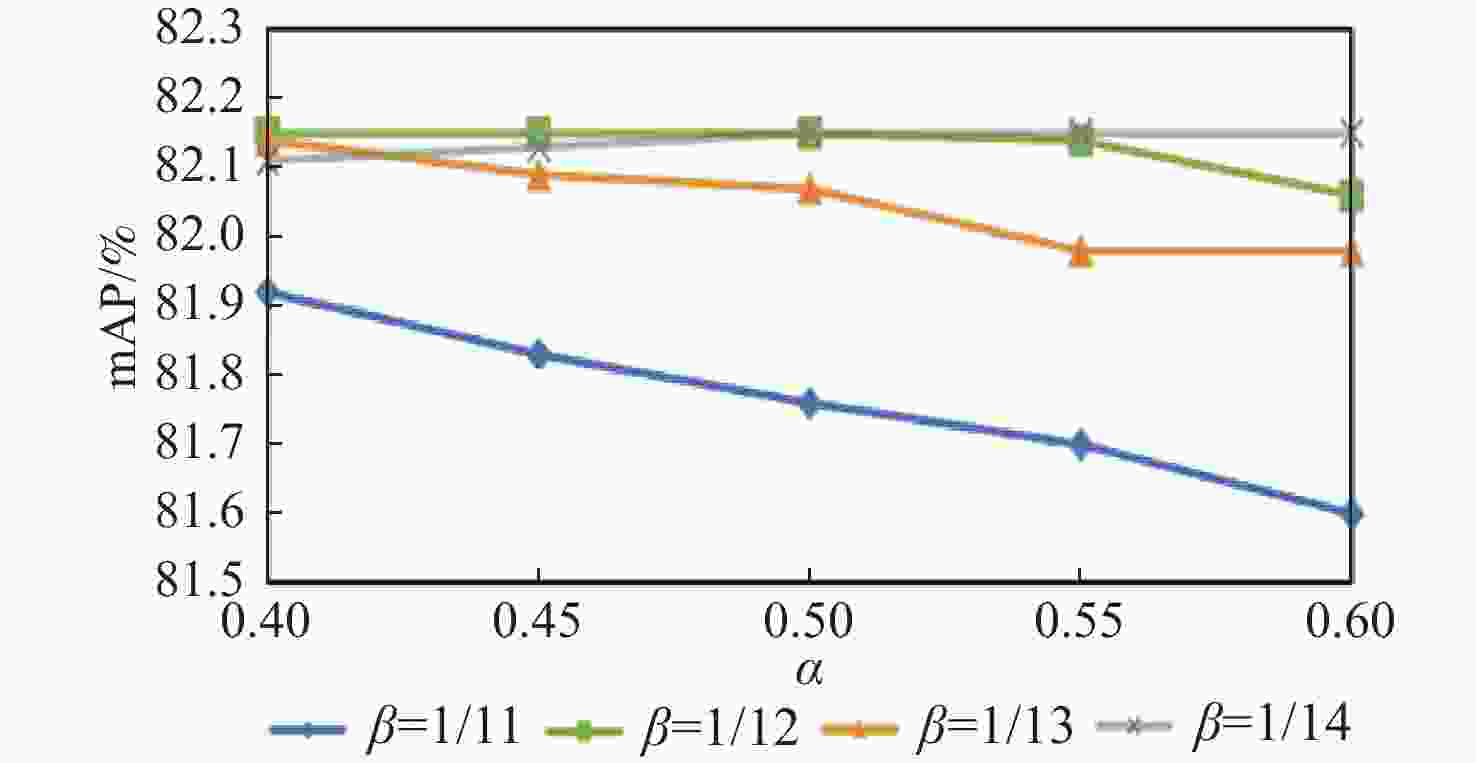
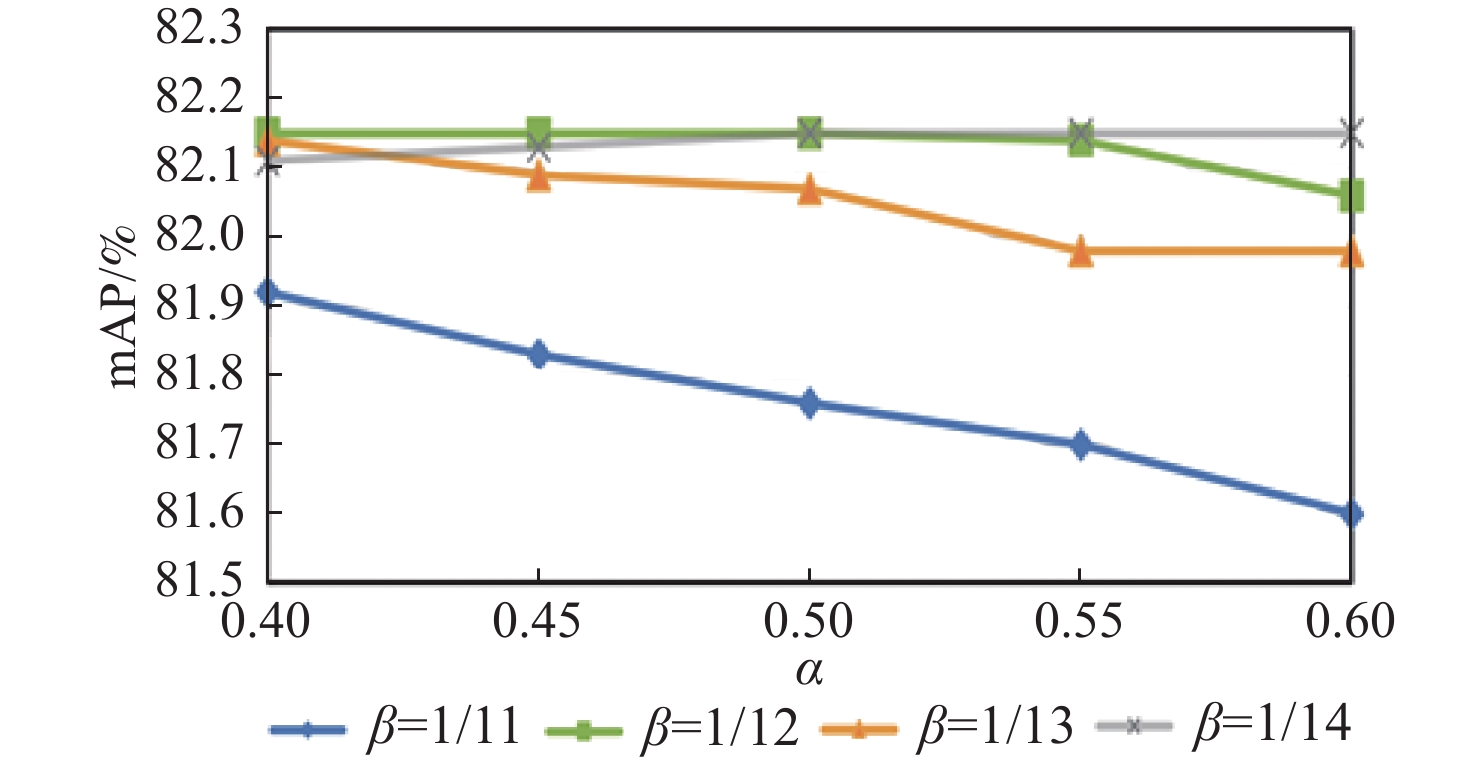
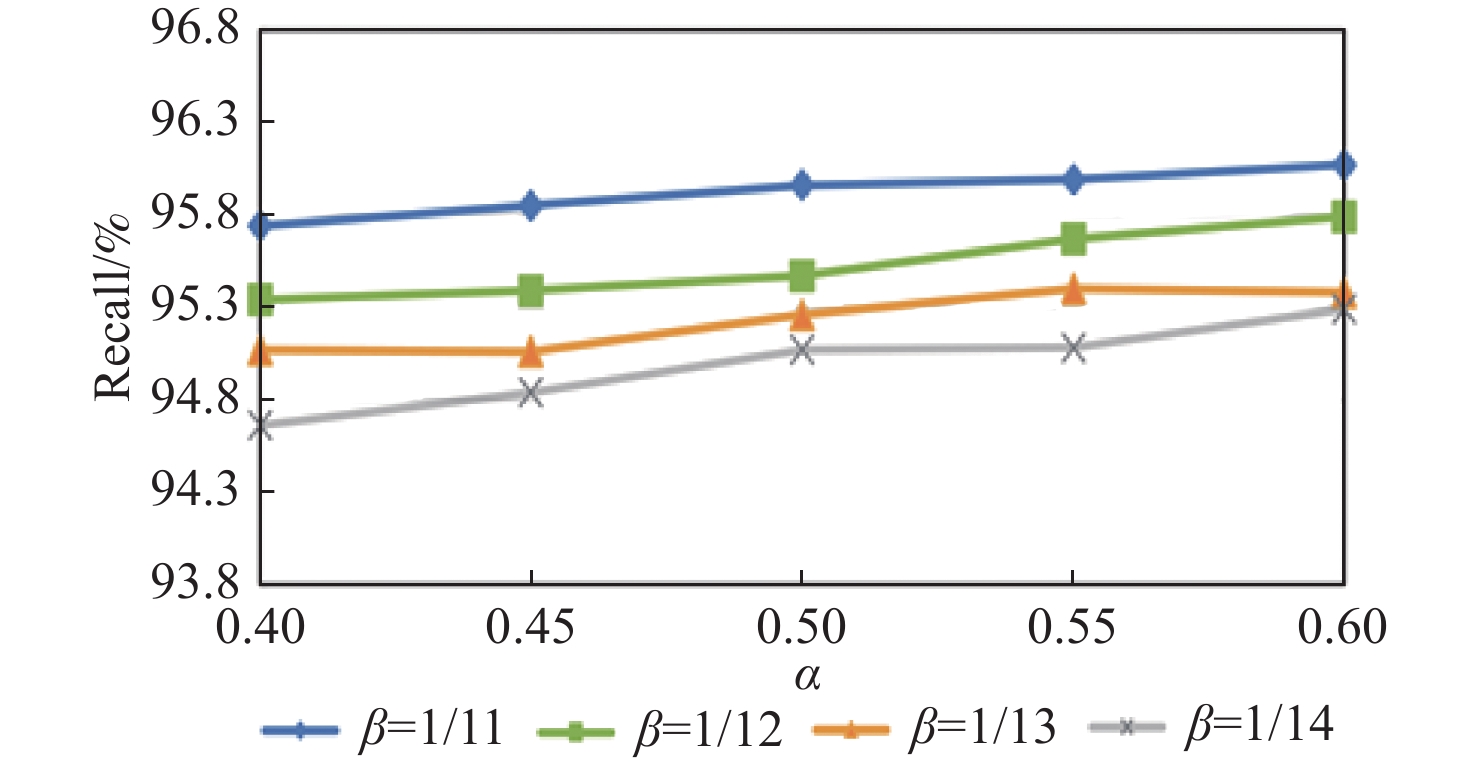
图 5 不同超参数设置下的检测精度
Figure 5. Detection accuracy under different hyperparameter settings
表 1 AMCM模块在PASCAL VOC上的有效性分析
Table 1. Effectiveness analysis of AMCM module on PASCAL VOC
基准算法 阈值 ASPP AMCM mAP/% Recall/% MR−2/% YOLOv4 ${N_{\mathrm{t}}} = 0.5$ 82.0 95.7 14.7 √ 82.6 96.2 14.4 √ 83.2 96.4 14.1  下载: 导出CSV
下载: 导出CSV
表 2 AMCM模块在KITTI上的有效性分析
Table 2. Effectiveness analysis of AMCM module on KITTI
基准算法 阈值 ASPP AMCM mAP/% Recall/% MR−2/% YOLOv4 ${N_{\mathrm{t}}} = 0.5$ 81.8 89.5 23.4 √ 82.9 90.4 22.8 √ 83.2 91.0 22.3
下载: 导出CSV
表 3 ADT-NMS在PASCAL VOC上的有效性分析
Table 3. Effectiveness analysis of ADT-NMS on PASCAL VOC
基准算法 AMCM ADT-NMS 阈值 mAP/% Recall/% MR−2/% YOLOv4 $ {N_{\mathrm{t}}} = 0.5 $ 82.00 95.7 14.7 √ $ {N_{\mathrm{t}}} = 0.5{[{\alpha ^2} + {({N^\beta } - 1)^2}]^{1/2}} $ 82.15 95.7 14.3 √ $ {N_{\mathrm{t}}} = \max ({d_{\mathrm{S}}},{d_{\mathrm{M}}},{d_{\mathrm{L}}}) $ 82.70 95.5 14.4 √ √ $ {N_{\mathrm{t}}} = \max ({d_{\mathrm{S}}},{d_{\mathrm{M}}},{d_{\mathrm{L}}}) $ 83.70 96.6 13.7
下载: 导出CSV
表 4 ADT-NMS在KITTI上的有效性分析
Table 4. Effectiveness analysis of ADT-NMS on KITTI
Baseline algorithm AMCM ADT-NMS 阈值 mAP/% Recall/% MR−2/% YOLOv4 $ {N_{\mathrm{t}}} = 0.5 $ 81.8 89.5 23.4 √ $ {N_{\mathrm{t}}} = 0.5{({\alpha ^2} + {({N^\beta } - 1)^2})^{1/2}} $ 82.3 90.9 23.1 √ $ {N_{\mathrm{t}}} = \max ({d_{\mathrm{S}}},{d_{\mathrm{M}}},{d_{\mathrm{L}}}) $ 82.5 91.2 23.0 √ √ $ {N_{\mathrm{t}}} = \max ({d_{\mathrm{S}}},{d_{\mathrm{M}}},{d_{\mathrm{L}}}) $ 83.6 91.8 22.1
下载: 导出CSV
表 5 本文算法和其他算法在PASAL VOC上整体性能对比
Table 5. Comparison of the overall performance the proposed algorithm and other algorithms on PASAL VOC
算法 骨干网络 图像大小/像素 mAP/% 帧率/(帧·s−1) Faster-RCNN [25] VGG-16 1000 ×60073.2 7 R-FCN [26] ResNet-101 1000 ×60080.5 9 CoupleNet [27] ResNet-101 1000 ×60082.7 8.2 SSD [28] VGG-16 512×512 76.8 19 DSSD513 [28] ResNet-101 513×513 81.5 5.5 YOLOv3 [29] DarkNet-53 544×544 79.3 26 RefineDet512 [30] VGG-16 512×512 81.8 24.1 ExtremeNet [32] Hourglass-104 512×512 79.3 3 FCOS [31] ResNet-50 800× 1333 81.1 10 CenterNet [32] ResNet-101 512×512 78.7 30 CenterNet-DHRNet [33] DHRNet 512×512 82.3 27.6 YOLOv4 [18] CSPDarkNet53 416×416 82.0 19.1 本文算法 CSPDarkNet53 416×416 83.7 16
下载: 导出CSV
表 6 本文算法和其他算法在KITTI上整体性能的对比
Table 6. Comparison of the overall performance the proposed algorithm and other algorithms on KITTI
下载: 导出CSV
-
[1] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2014: 580-587. [2] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 779-788. [3] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[EB/OL]. (2017-06-12)[2023-02-01]. http://arxiv.org/abs/1706.03762. [4] ZHU X Z, SU W J, LU L W, et al. Deformable DETR: deformable transformers for end-to-end object detection[EB/OL]. (2021-03-18)[2023-02-01]. http://arxiv.org/abs/2010.04159. [5] NEUBECK A, VAN GOOL L. Efficient non-maximum suppression[C]//Proceedings of the 18th International Conference on Pattern Recognition. Piscataway: IEEE Press, 2006: 850-855. [6] GONG Y Q, YU X H, DING Y, et al. Effective fusion factor in FPN for tiny object detection[C]//Proceedings of the IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE Press, 2021: 1159-1167. [7] LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 8759-8768. [8] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 936-944. [9] SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 2818-2826. [10] 许腾, 唐贵进, 刘清萍, 等. 基于空洞卷积和Focal Loss的改进YOLOv3算法[J]. 南京邮电大学学报(自然科学版), 2020, 40(6): 100-108.XU T, TANG G J, LIU Q P, et al. Improved YOLOv3 based on dilated convolution and focal loss[J]. Journal of Nanjing University of Posts and Telecommunications (Natural Science Edition), 2020, 40(6): 100-108(in Chinese). [11] 王囡, 侯志强, 蒲磊, 等. 空洞可分离卷积和注意力机制的实时语义分割[J]. 中国图象图形学报, 2022, 27(4): 1216-1225. doi: 10.11834/jig.200729WANG N, HOU Z Q, PU L, et al. Real-time semantic segmentation analysis based on cavity separable convolution and attention mechanism[J]. Journal of Image and Graphics, 2022, 27(4): 1216-1225(in Chinese). doi: 10.11834/jig.200729 [12] 肖进胜, 张舒豪, 陈云华, 等. 双向特征融合与特征选择的遥感影像目标检测[J]. 电子学报, 2022, 50(2): 267-272. doi: 10.12263/DZXB.20210354XIAO J S, ZHANG S H, CHEN Y H, et al. Remote sensing image object detection based on bidirectional feature fusion and feature selection[J]. Acta Electronica Sinica, 2022, 50(2): 267-272(in Chinese). doi: 10.12263/DZXB.20210354 [13] 谢学立, 李传祥, 杨小冈, 等. 基于动态感受野的航拍图像目标检测算法[J]. 光学学报, 2020, 40(4): 0415001. doi: 10.3788/AOS202040.0415001XIE X L, LI C X, YANG X G, et al. Dynamic receptive field-based object detection in aerial imaging[J]. Acta Optica Sinica, 2020, 40(4): 0415001(in Chinese). doi: 10.3788/AOS202040.0415001 [14] BODLA N, SINGH B, CHELLAPPA R, et al. Soft-NMS: improving object detection with one line of code[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 5562-5570. [15] 侯志强, 刘晓义, 余旺盛, 等. 基于双阈值-非极大值抑制的Faster R-CNN改进算法[J]. 光电工程, 2019, 46(12): 190159.HOU Z Q, LIU X Y, YU W S, et al. Improved algorithm of Faster R-CNN based on double threshold-non-maximum suppression[J]. Opto-Electronic Engineering, 2019, 46(12): 190159(in Chinese). [16] JIANG B R, LUO R X, MAO J Y, et al. Acquisition of localization confidence for accurate object detection[M]// Computer Vision——ECCV 2018. Berlin: Springer, 2018: 816-832. [17] HENDERSON P, FERRARI V. End-to-end training of object class detectors for mean average precision[M]//Computer Vision——ACCV 2016. Berlin: Springer, 2017: 198-213. [18] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. Yolov4: optimal speed and accuracy of object detection[EB/OL]. (2020-04-23)[ 2023-02-01]. http://arxiv.org/abs/2004.10934. [19] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778. [20] HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916. doi: 10.1109/TPAMI.2015.2389824 [21] ZHENG Z H, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020, 34(7): 12993-13000. [22] LIU W, LIAO S C, REN W Q, et al. High-level semantic feature detection: a new perspective for pedestrian detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 5182-5191. [23] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848. doi: 10.1109/TPAMI.2017.2699184 [24] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7132-7141. [25] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. doi: 10.1109/TPAMI.2016.2577031 [26] DAI J F, LI Y, HE K M, et al. R-FCN: object detection via region-based fully convolutional networks[EB/OL]. (2016-05-20)[2023-02-01]. http://arxiv.org/abs/1605.06409. [27] ZHU Y S, ZHAO C Y, WANG J Q, et al. CoupleNet: coupling global structure with local parts for object detection[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 4146-4154. [28] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[M]//Computer Vision——ECCV 2016. Berlin: Springer, 2016: 21-37. [29] REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. (2018-04-08)[2023-02-01]. http://arxiv.org/abs/1804.02767. [30] ZHANG S F, WEN L Y, BIAN X, et al. Single-shot refinement neural network for object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 4203-4212. [31] TIAN Z, SHEN C H, CHEN H, et al. FCOS: fully convolutional one-stage object detection[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 9626-9635. [32] DUAN K W, BAI S, XIE L X, et al. CenterNet: keypoint triplets for object detection[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 6568-6577. [33] ZHOU X Y, WANG D Q, KRÄHENBÜHL P. Objects as points[EB/OL]. (2019-04-25)[2023-02-01]. http://arxiv.org/abs/1904.07850. [34] 高扬, 安雯. 基于可变空间感知的目标检测算法[J]. 现代电子技术, 2023, 46(12): 91-95.GAO Y, AN W. Object detection algorithm based on variable spatial perception[J]. Modern Electronics Technique, 2023, 46(12): 91-95(in Chinese). -

 下载:
下载:
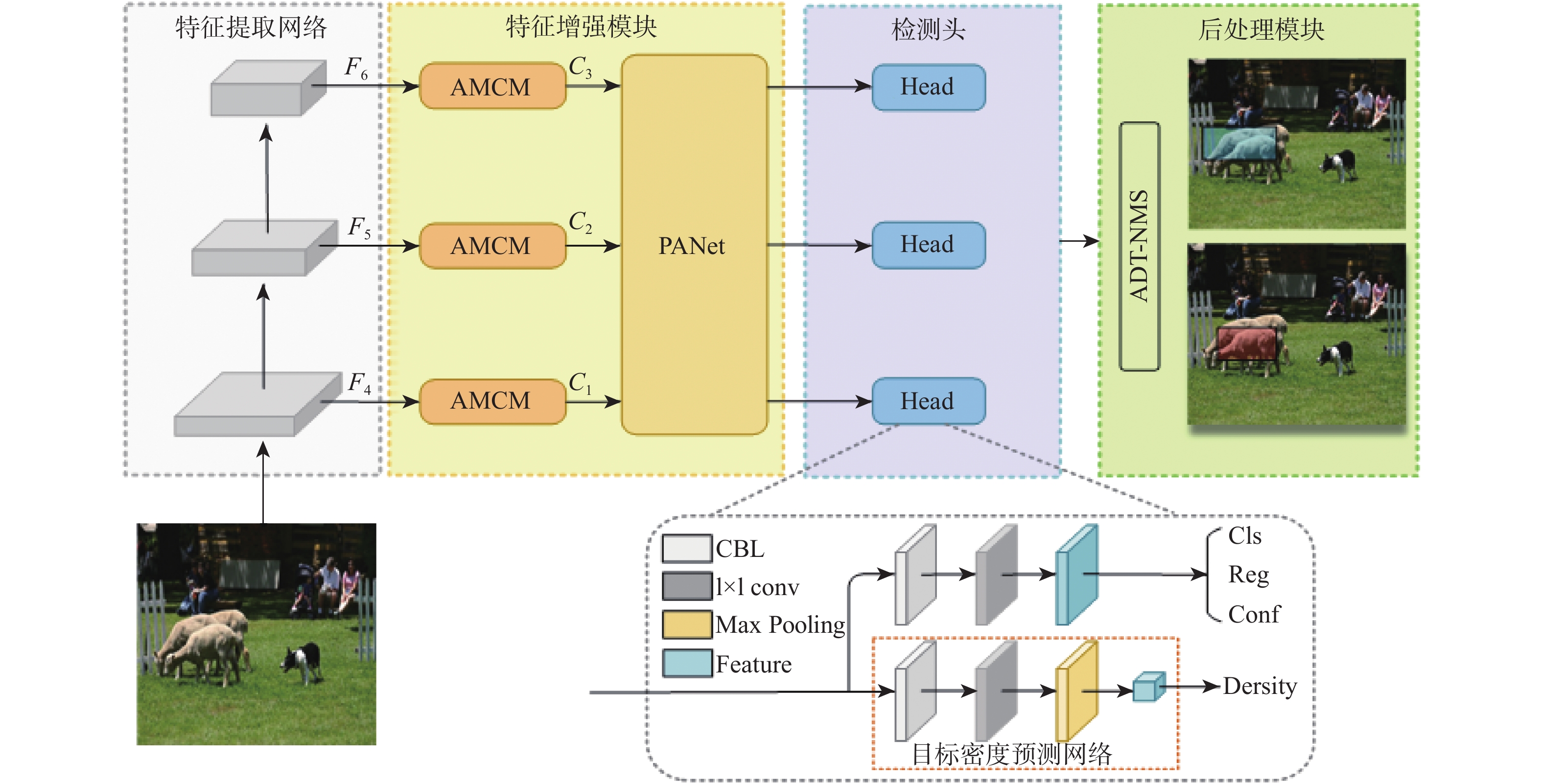
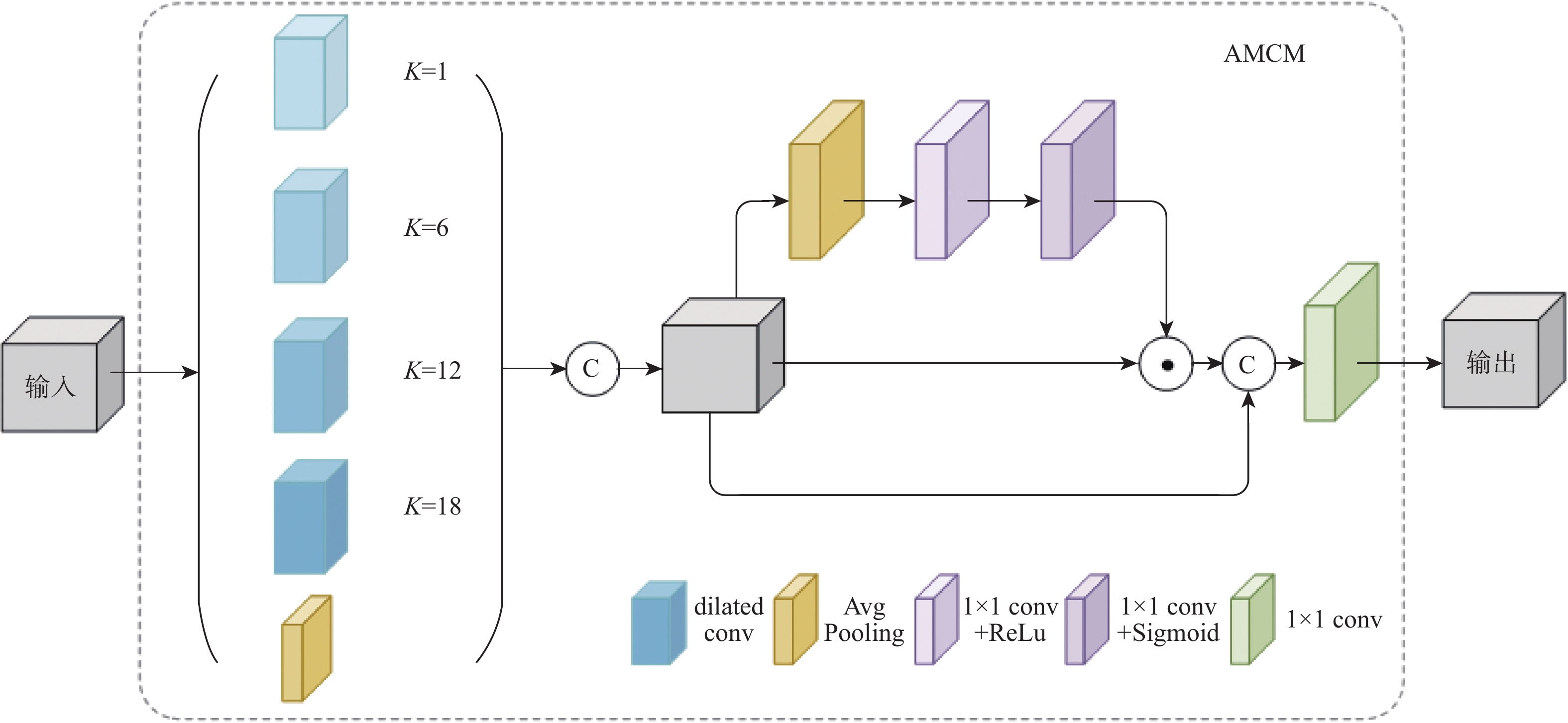
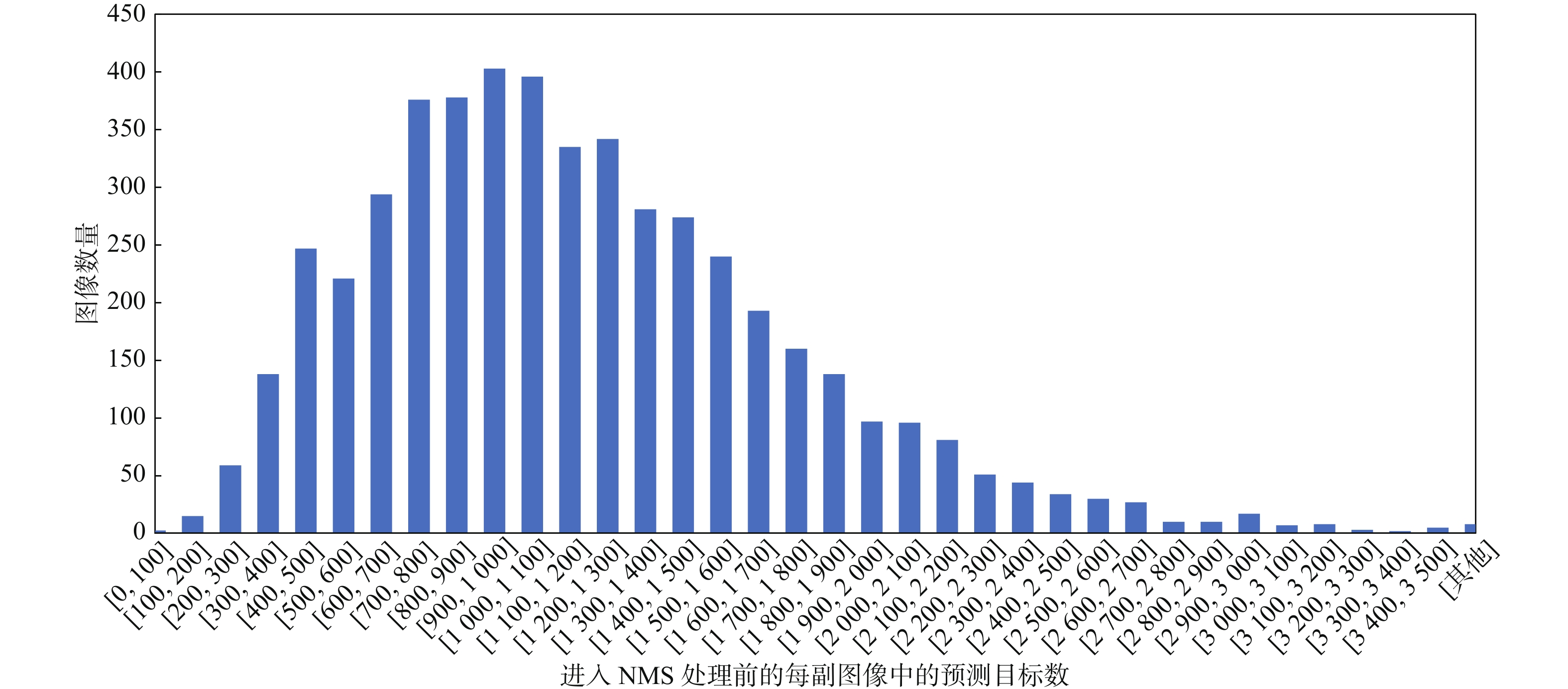



 点击查看大图
点击查看大图
计量
- 文章访问数: 662
- HTML全文浏览量: 101
- PDF下载量: 10
- 被引次数: 0
