



Efficient weakly-supervised video moment retrieval algorithm without multimodal fusion
-
摘要:
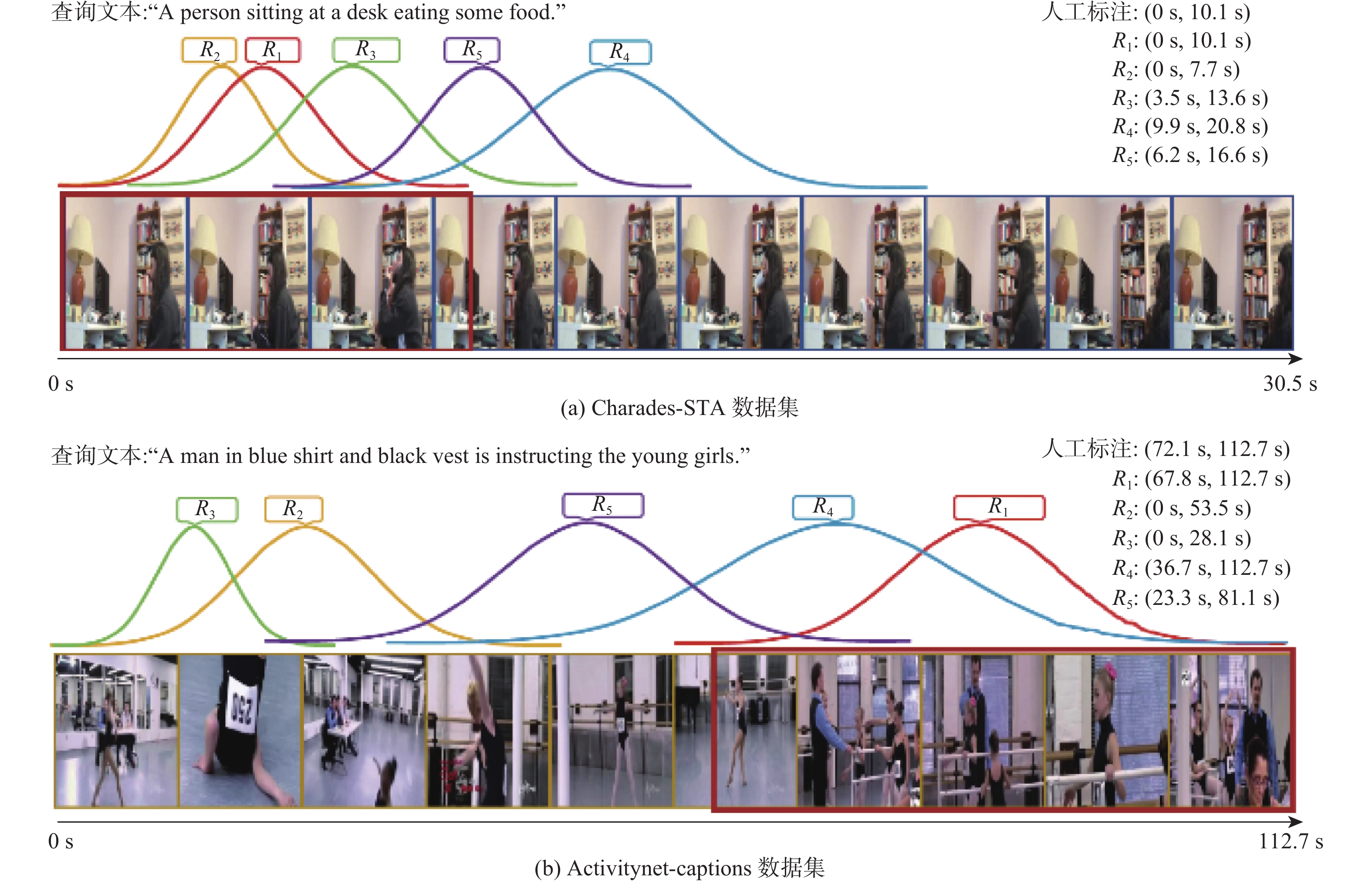
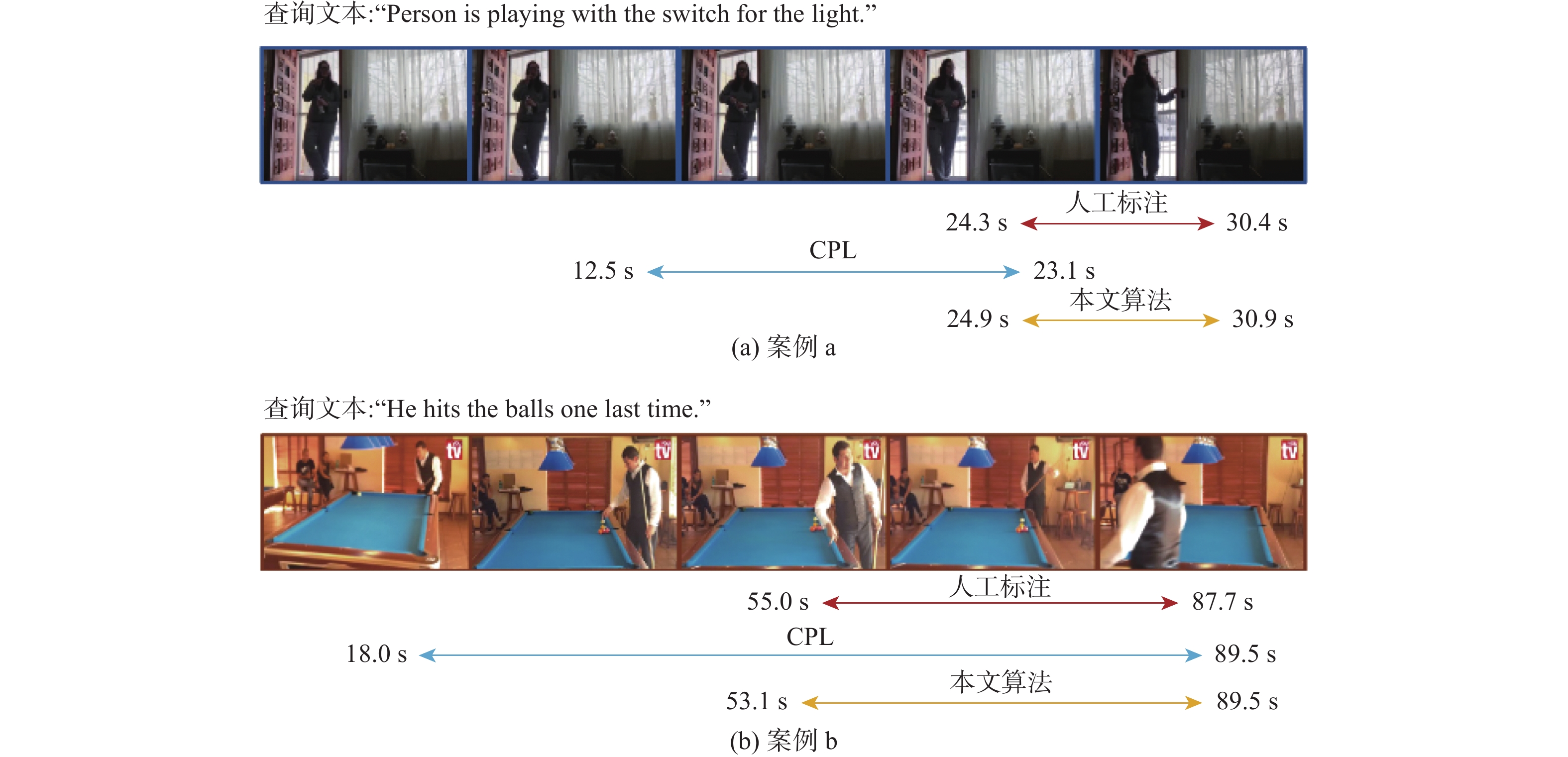
弱监督视频时刻检索(WSVMR)旨在基于视频与自然语言文本的匹配关系训练深度学习算法模型,以实现根据自然语言查询文本从未经修剪的视频中检索特定事件内容的起始与结束时间。 大多数现有的WSVMR算法采用多模态融合机制来理解视频内容以完成时刻检索,限制了现有算法的运行效率,降低了该项技术在多媒体应用中的实用性。基于此,提出一种可实现快速WSVMR的无融合多模态对齐网络(FMAN)算法。该算法可以将复杂的跨模态交互计算全部限制在训练阶段,从而允许模型对视频数据和文本数据都进行离线编码,显著提高了视频时刻检索的推理速度。在Charades-STA数据集和ActivityNet-Captions数据集上的实验结果表明:FMAN算法所取得的检索性能与效率都优于现有算法:对于衡量检索性能的指标
R 1召回率和R 5召回率,在Charades-STA数据集上,所提算法分别平均取得了2.66%和1.57%的性能提升;在ActivityNet-Captions数据集上,所提算法分别平均取得了0.19%和3.35%的性能提升;在检索效率上,所提算法将在线每秒浮点运算次数降低至原有算法的1%以下。Abstract:The weakly-supervised video moment retrieval (WSVMR) task retrieves in and out points of specific events from untrimmed videos based on natural language query text, using a deep learning algorithm model trained through video and natural language text matching relationships. Most existing WSVMR algorithms use multimodal fusion mechanisms to understand video content for moment retrieval. However, the cross-modal interactions required for effective fusion are quite complex, and this process can only be initiated once a clear user query is received. These hinder the operational efficiency of these algorithms, limiting their deployment in multimedia applications. To address this issue, a novel fusion-free multimodal alignment network (FMAN) algorithm for achieving rapid WSVMR was proposed. By restricting complex cross-modal interaction computation in the training phase, this algorithm enables offline encoding of both video and text data by the model, thereby significantly improving the inference speed of video moment retrieval. Experimental results on Charades-STA and ActivityNet-Captions datasets show FMAN’s superior retrieval performance and efficiency compared to existing methods. The experiment on retrieval performance metrics, specifically recall rates (
R 1 andR 5), shows an average improvement of 2.66% and 1.57% on Charades-STA, as well as 0.19% and 3.35% on ActivityNet-Captions, respectively. Additionally, the proposed algorithm reduces online floating-point operations per second to no more than 1% of the original algorithm. -
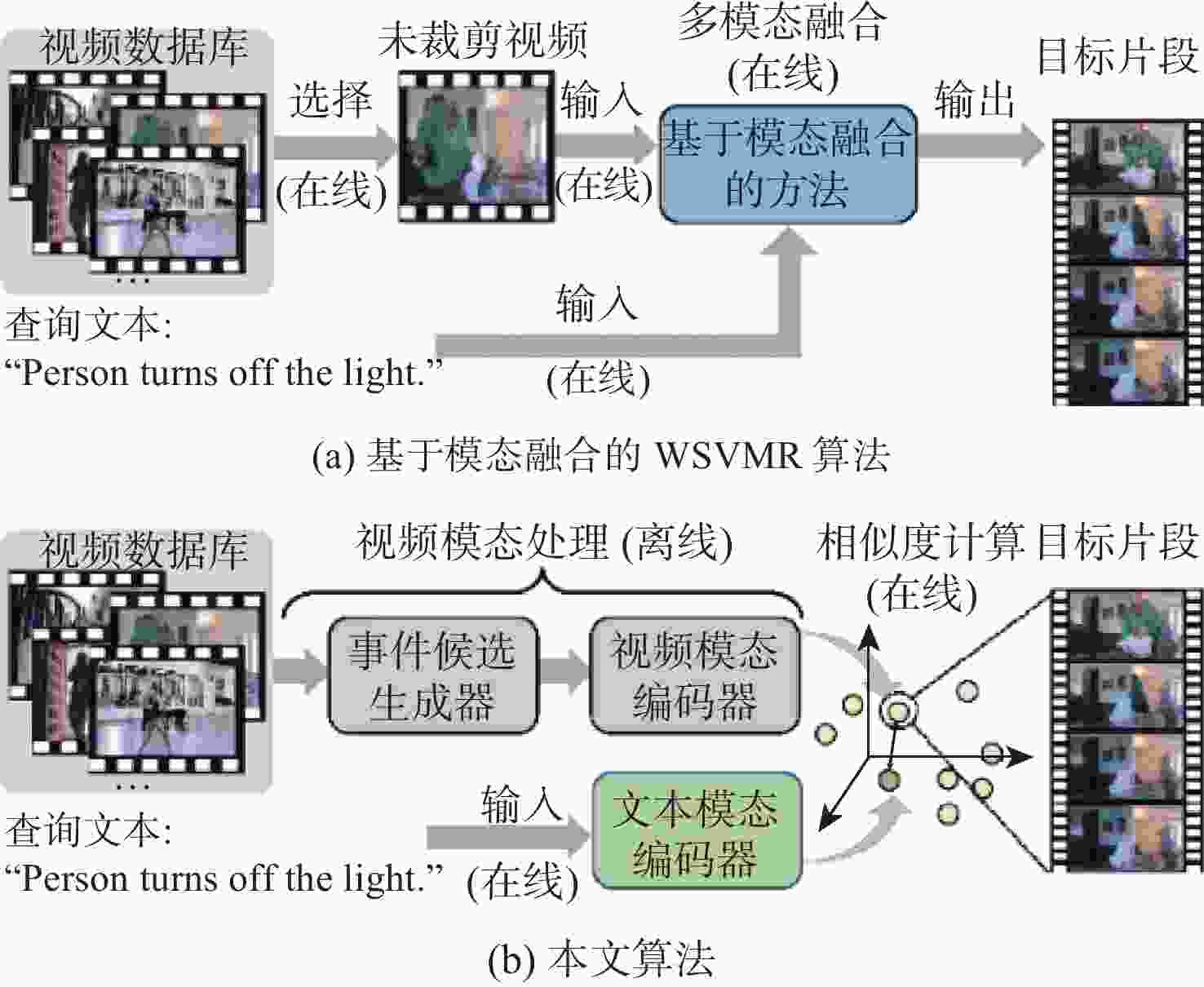
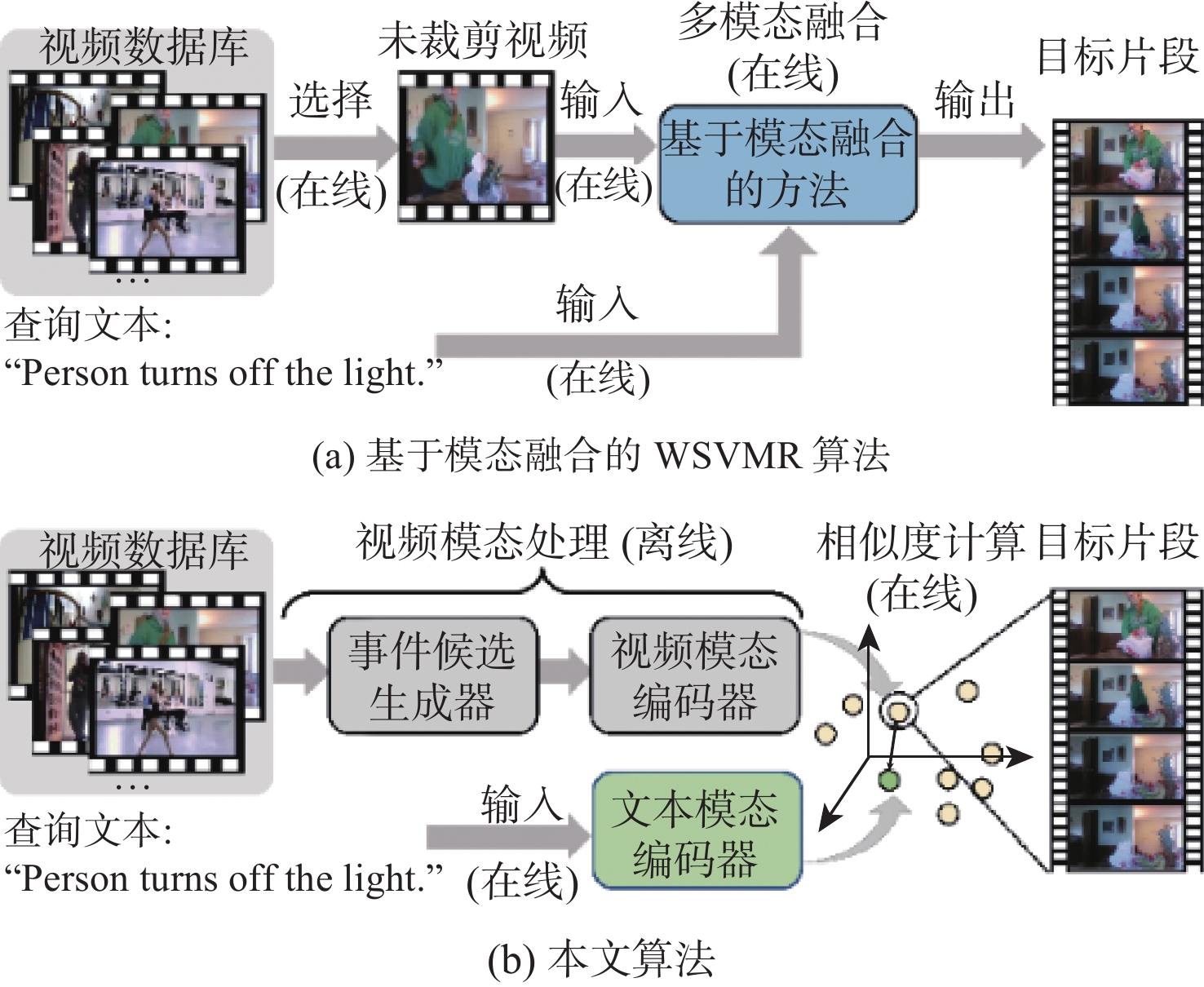
图 1 现有基于模态融合的算法与本文算法的示意图
Figure 1. Diagrams of existing modal fusion-based algorithms and the proposed algorithm
表 1 在不同数据集上的检索性能对比
Table 1. Comparison of retrieval performance on different datasets
类型 算法 召回率/% Charades-STA数据集 ActivityNet-Captions数据集 n=1, n=1, n=1, n=5, n=5, n=5, n=1, n=1, n=1, n=5, n=5, n=5, m=0.5 m=0.7 Avg. m=0.5 m=0.7 Avg. m=0.3 m=0.5 Avg. m=0.3 m=0.5 Avg. 全监督 2DTAN[2] 39.70 23.31 31.51 80.32 51.26 65.79 59.45 44.51 51.98 85.53 77.13 81.33 LGI [3] 59.46 35.48 47.47 58.52 41.51 50.02 SDN[4] 60.27 41.48 50.88 63.00 42.41 52.71 点监督 ViGA[5] 45.05 20.27 32.66 59.61 35.79 47.70 D3G[27] 41.64 19.60 30.62 79.25 49.30 64.28 58.25 36.68 47.47 87.84 74.21 81.03 CFMR[7] 48.14 22.58 35.36 80.06 56.09 68.08 59.97 36.97 48.47 82.68 69.28 75.98 弱监督 SCN[15] 23.58 9.97 16.78 71.80 38.87 55.34 47.23 29.22 38.23 71.56 55.69 63.63 LCNet[10] 39.19 18.87 29.03 80.56 45.24 62.90 48.49 26.33 37.41 82.51 62.66 72.59 DCCP[28] 29.80 11.90 20.85 77.20 32.20 54.70 41.60 23.20 32.40 61.40 41.70 51.55 EVA[11] 40.21 18.22 29.22 49.89 29.43 39.66 ProTeGe[6] 31.84 17.51 24.68 45.02 27.85 36.44 CWG[12] 31.02 16.53 23.78 77.53 41.91 59.72 46.62 29.52 38.07 80.92 66.61 73.77 CPL[9] 49.24 22.39 35.82 84.71 52.37 68.54 50.07 30.14 40.11 81.32 65.79 73.56 FMAN 51.40 25.05 38.23 86.29 53.93 70.11 50.01 30.58 40.30 83.75 70.48 77.12  下载: 导出CSV
下载: 导出CSV
表 2 在Charades-STA数据集上的检索效率对比
Table 2. Comparison of retrieval efficiency on Charades-STA dataset
下载: 导出CSV
表 3 Charades-STA数据集上的消融实验
Table 3. Ablation study on Charades-STA dataset
% $ \mathcal{L}_{\mathrm{cma}} $ $ \mathcal{L}_{\operatorname{ivc}} $ $ \mathcal{L}_{\mathrm{cvc}} $ R1 R5 m=0.5 m=0.7 m=0.5 m=0.7 × × × 46.82 20.66 82.06 50.48 √ × × 48.41 21.52 82.92 50.70 √ √ × 48.87 22.17 84.40 51.67 √ × √ 50.86 23.09 86.29 53.04 √ √ √ 51.40 25.05 86.29 53.93
下载: 导出CSV
-
[1] GAO J Y, SUN C, YANG Z H, et al. TALL: temporal activity localization via language query[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 5277-5285. [2] ZHANG S Y, PENG H W, FU J L, et al. Learning 2D temporal adjacent networks for moment localization with natural language[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 12870-12877. doi: 10.1609/aaai.v34i07.6984 [3] MUN J, CHO M, HAN B. Local-global video-text interactions for temporal grounding[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 10807-10816. [4] JIANG X, XU X, ZHANG J R, et al. SDN: semantic decoupling network for temporal language grounding[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(5): 6598-6612. doi: 10.1109/TNNLS.2022.3211850 [5] CUI R, QIAN T W, PENG P, et al. Video moment retrieval from text queries via single frame annotation[C]//Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2022: 1033-1043. [6] WANG L, MITTAL G, SAJEEV S, et al. ProTéGé: untrimmed pretraining for video temporal grounding by video temporal grounding[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2023: 6575-6585. [7] JIANG X, ZHOU Z L, XU X, et al. Faster video moment retrieval with point-level supervision[EB/OL]. (2023-01-23)[2023-02-01]. http://arxiv.org/abs/2305.14017v1. [8] JI W, LIANG R J, ZHENG Z D, et al. Are binary annotations sufficient? video moment retrieval via hierarchical uncertainty-based active learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2023: 23013-23022. [9] ZHENG M H, HUANG Y J, CHEN Q C, et al. Weakly supervised temporal sentence grounding with Gaussian-based contrastive proposal learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 15534-15543. [10] YANG W F, ZHANG T Z, ZHANG Y D, et al. Local correspondence network for weakly supervised temporal sentence grounding[J]. IEEE Transactions on Image Processing, 2021, 30: 3252-3262. doi: 10.1109/TIP.2021.3058614 [11] CAI W T, HUANG J B, GONG S G. Hybrid-learning video moment retrieval across multi-domain labels[EB/OL]. (2022-12-23)[2023-02-01]. http://arxiv.org/abs/2406.01791. [12] CHEN J M, LUO W X, ZHANG W, et al. Explore inter-contrast between videos via composition for weakly supervised temporal sentence grounding[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2022, 36(1): 267-275. doi: 10.1609/aaai.v36i1.19902 [13] WU Q, CHEN Y F, HUANG N, et al. Weakly-supervised cerebrovascular segmentation network with shape prior and model indicator[C]//Proceedings of the International Conference on Multimedia Retrieval. New York: ACM, 2022: 668-676. [14] 丁家满, 刘楠, 周蜀杰, 等. 基于正则化的半监督弱标签分类算法[J]. 计算机学报, 2022, 45(1): 69-81. doi: 10.11897/SP.J.1016.2022.00069DING J M, LIU N, ZHOU S J, et al. Semi-supervised weak-label classification method by regularization[J]. Chinese Journal of Computers, 2022, 45(1): 69-81(in Chinese). doi: 10.11897/SP.J.1016.2022.00069 [15] LIN Z J, ZHAO Z, ZHANG Z, et al. Weakly-supervised video moment retrieval via semantic completion network[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 11539-11546. doi: 10.1609/aaai.v34i07.6820 [16] JIANG X, XU X, ZHANG J R, et al. Semi-supervised video paragraph grounding with contrastive encoder[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 2456-2465. [17] XU X, WANG T, YANG Y, et al. Cross-modal attention with semantic consistence for image–text matching[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(12): 5412-5425. doi: 10.1109/TNNLS.2020.2967597 [18] JIANG X, XU X, CHEN Z G, et al. DHHN: dual hierarchical hybrid network for weakly-supervised audio-visual video parsing[C]//Proceedings of the 30th ACM International Conference on Multimedia. New York: ACM, 2022: 719-727. [19] 刘耀胜, 廖育荣, 林存宝, 等. 基于特征融合与抗遮挡的卫星视频目标跟踪算法[J]. 北京亚洲成人在线一二三四五六区学报, 2022, 48(12): 2537-2547.LIU Y S, LIAO Y R, LIN C B, et al. Feature-fusion and anti-occlusion based target tracking method for satellite videos[J]. Journal of Beijing University of Aeronautics and Astronautics, 2022, 48(12): 2537-2547(in Chinese). [20] 张燕咏, 张莎, 张昱, 等. 基于多模态融合的自动驾驶感知及计算[J]. 计算机研究与发展, 2020, 57(9): 1781-1799. doi: 10.7544/issn1000-1239.2020.20200255ZHANG Y Y, ZHANG S, ZHANG Y, et al. Multi-modality fusion perception and computing in autonomous driving[J]. Journal of Computer Research and Development, 2020, 57(9): 1781-1799(in Chinese). doi: 10.7544/issn1000-1239.2020.20200255 [21] JIANG X, XU X, ZHANG J R, et al. GTLR: graph-based transformer with language reconstruction for video paragraph grounding[C]//Proceedings of the IEEE International Conference on Multimedia and Expo. Piscataway: IEEE Press, 2022: 1-6. [22] CARREIRA J, ZISSERMAN A. Quo vadis, action recognition? a new model and the kinetics dataset[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 4724-4733. [23] PENNINGTON J, SOCHER R, MANNING C. Glove: global vectors for word representation[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Stroudsburg: USAACL, 2014: 1532-1543. [24] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[EB/OL]. (2017-06-12)[2023-02-01]. http://arxiv.org/abs/1706.03762. [25] KRISHNA R, KENJI H T, REN F, et al. Dense-captioning events in videos[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 706-715. [26] KINGMA D P, BA J, HAMMAD M M. Adam: a method for stochastic optimization[EB/OL]. (2017-01-30)[2023-02-01]. http://arxiv.org/abs/1412.6980v9. [27] LI H J, SHU X J, HE S N, et al. D3G: exploring Gaussian prior for temporal sentence grounding with glance annotation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2023: 13688-13700. [28] MA F, ZHU L C, YANG Y. Weakly supervised moment localization with decoupled consistent concept prediction[J]. International Journal of Computer Vision, 2022, 130(5): 1244-1258. doi: 10.1007/s11263-022-01600-0 -

 下载:
下载:


 点击查看大图
点击查看大图
计量
- 文章访问数: 292
- HTML全文浏览量: 91
- PDF下载量: 9
- 被引次数: 0
