| Citation: | LUO Q Y,ZHANG T Q,XIONG T. Singing voice separation method using multi-stage progressive gated convolutional network[J]. Journal of Beijing University of Aeronautics and Astronautics,2025,51(9):2872-2881 (in Chinese) doi: 10.13700/j.bh.1001-5965.2023.0419

|
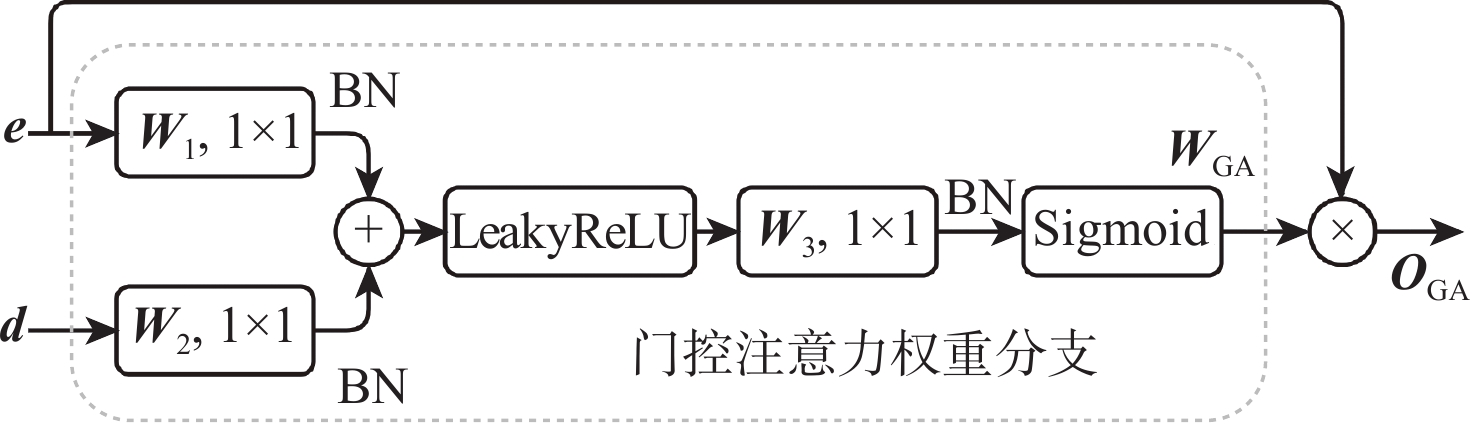
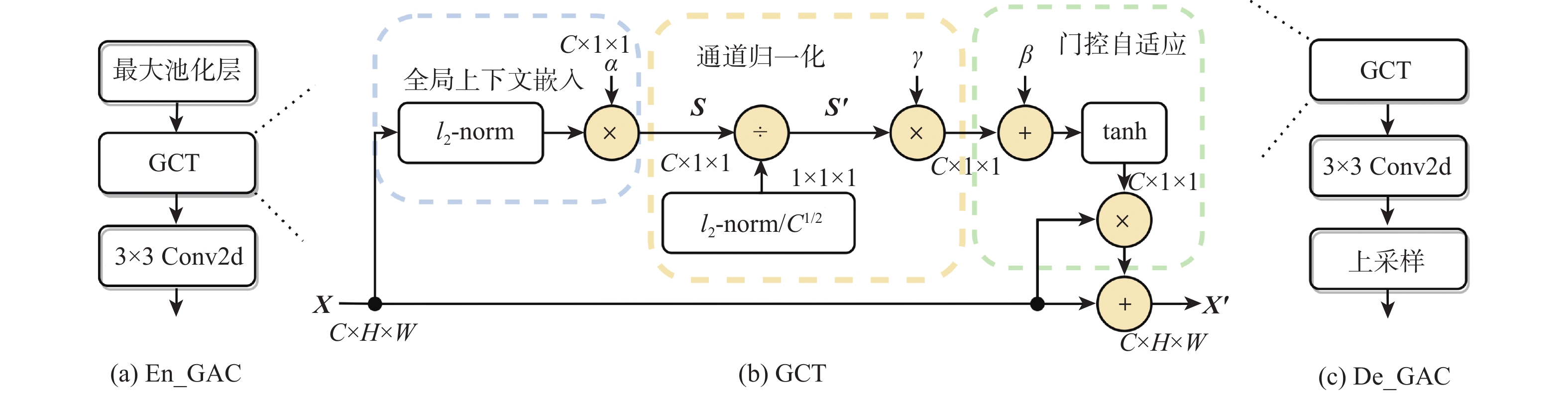
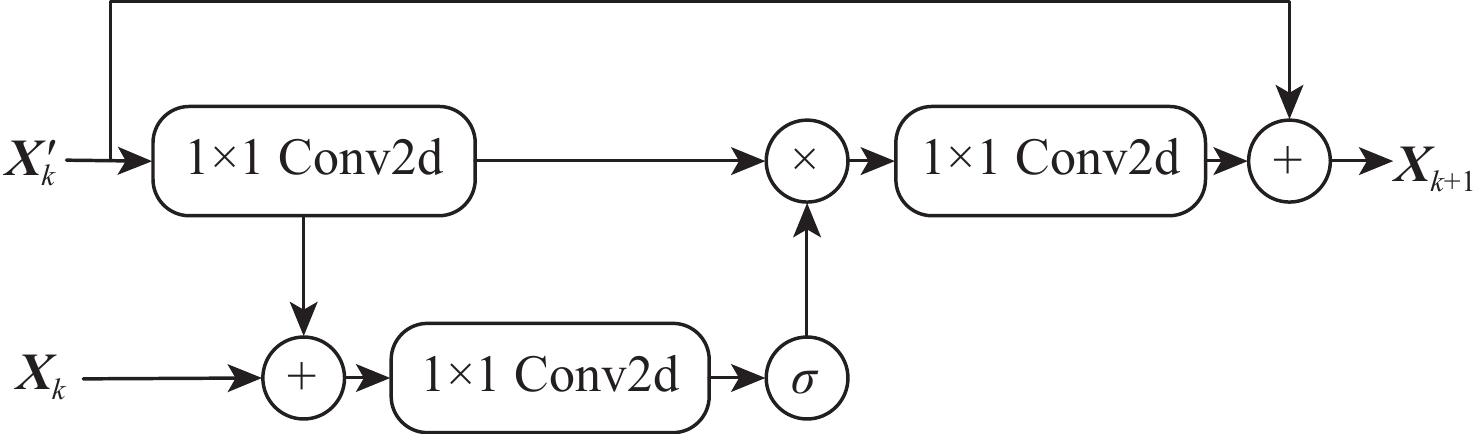
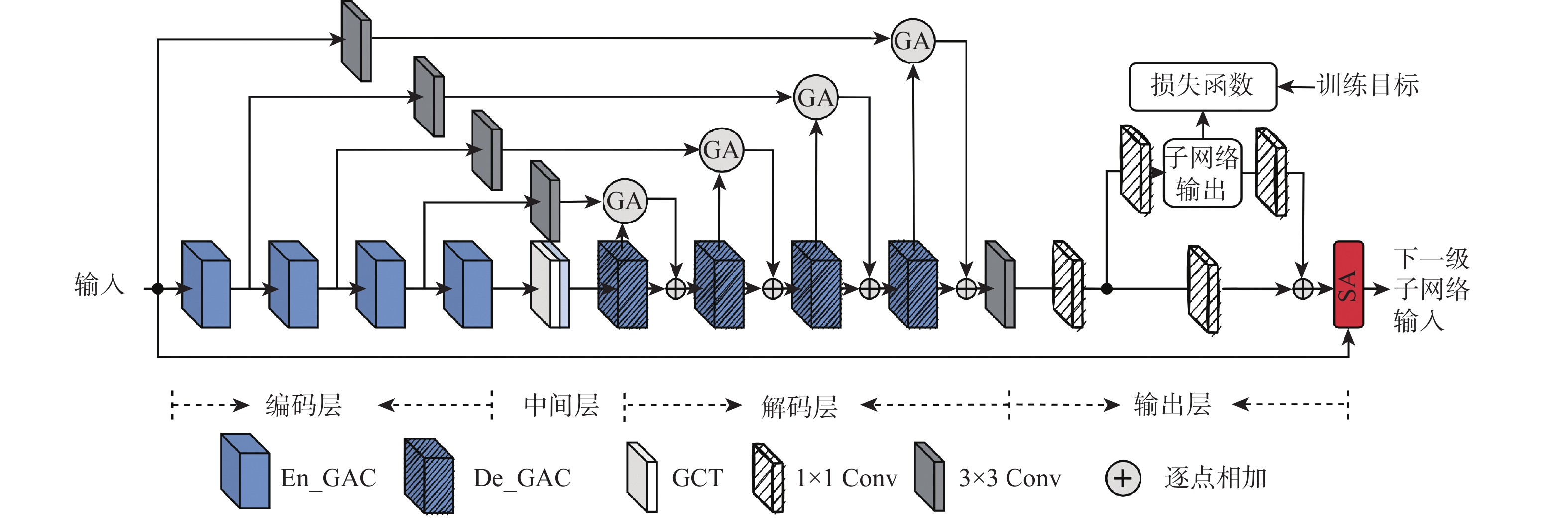
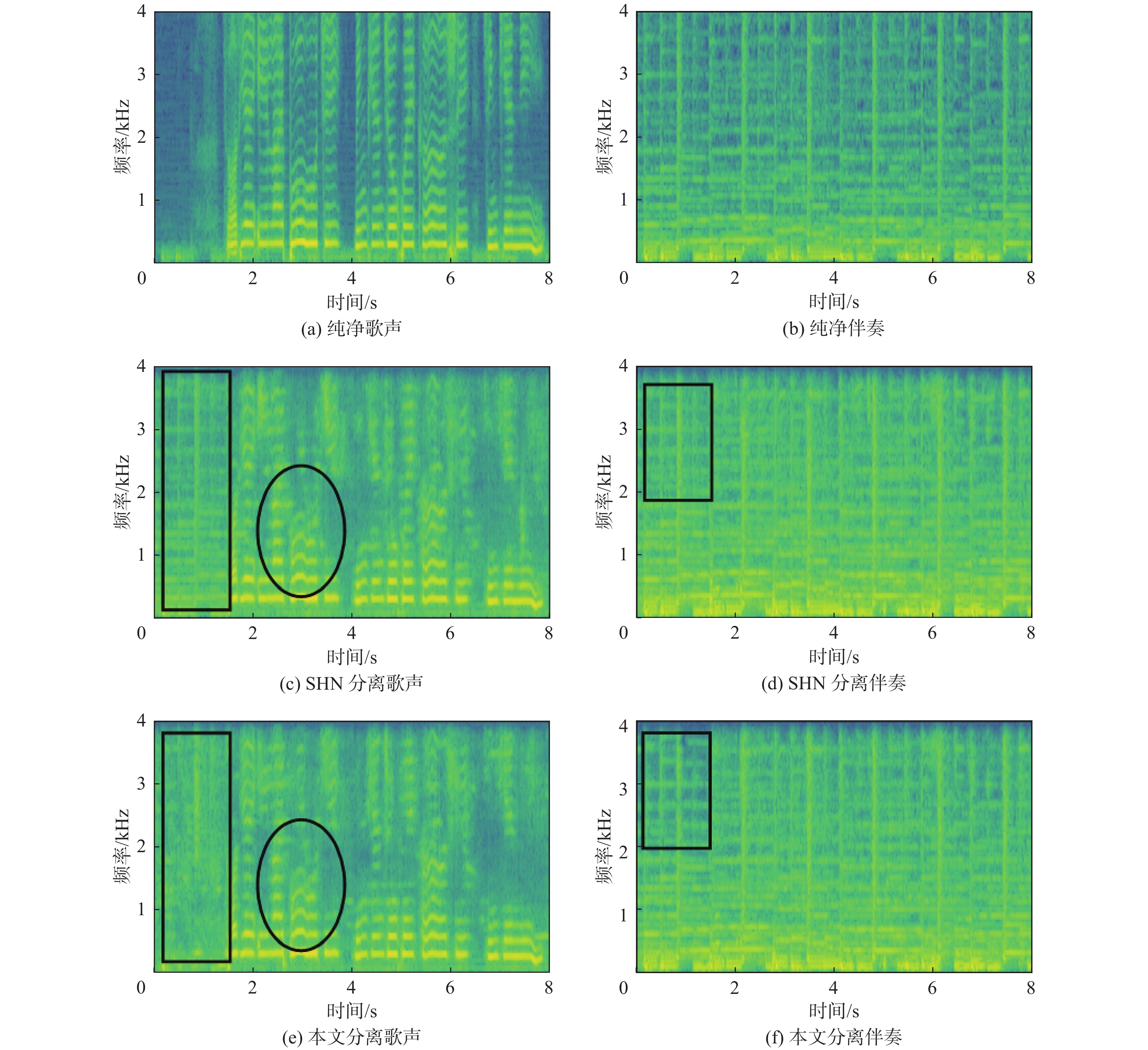
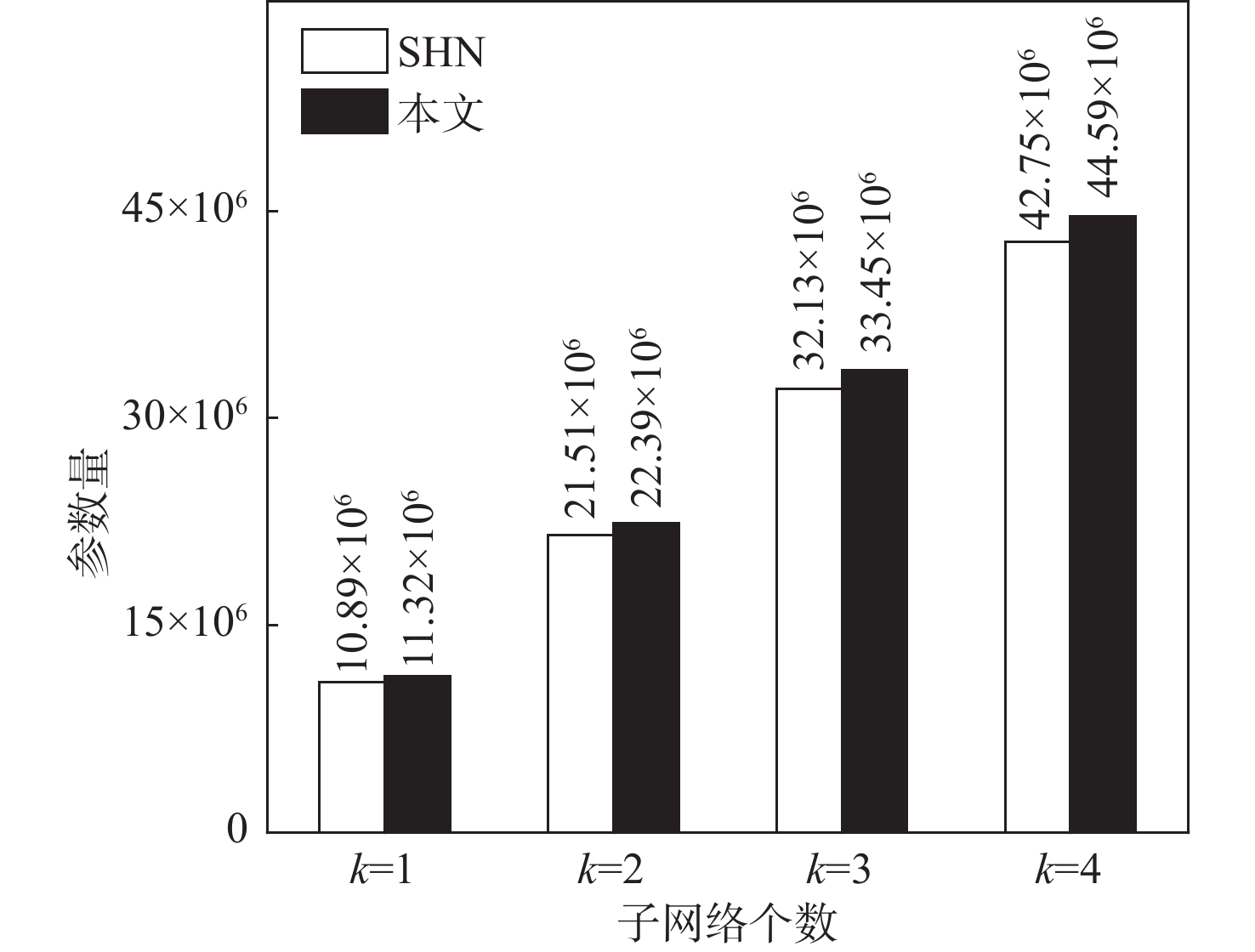
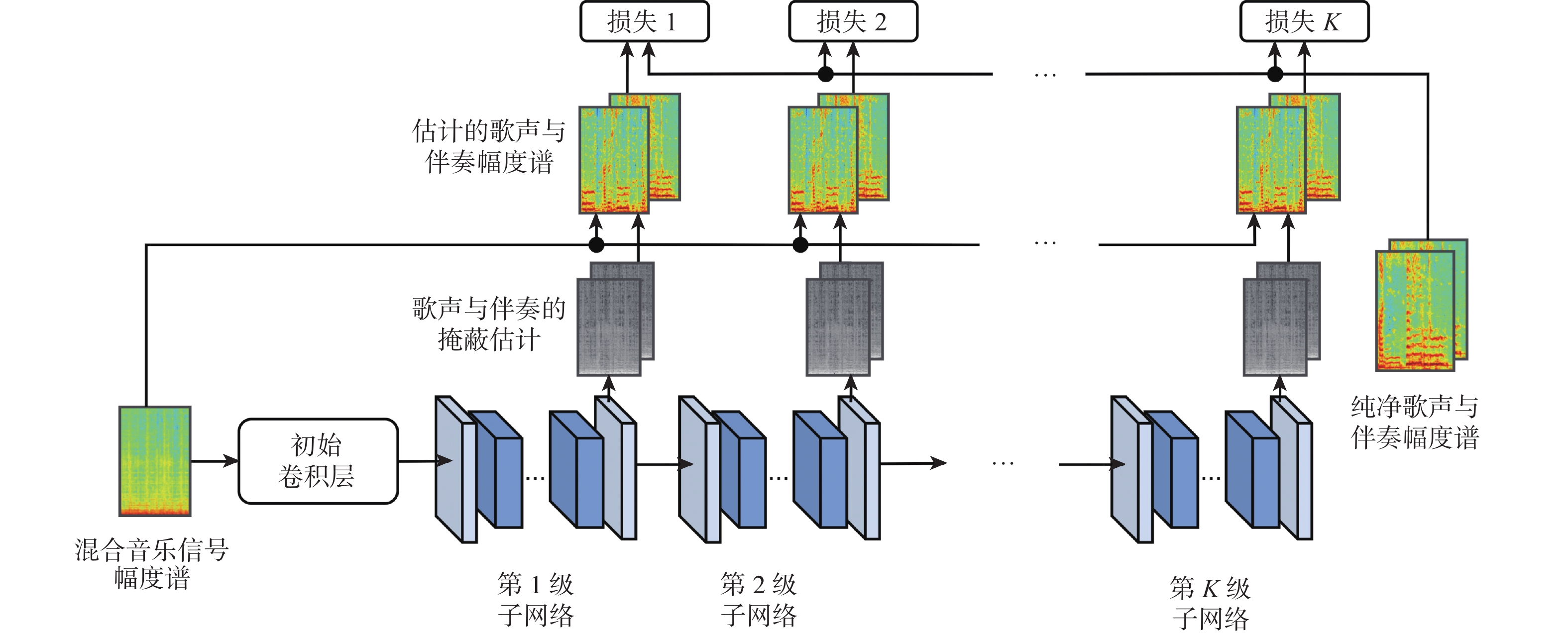
To solve the problems that current singing voice separation algorithms based on convolutional neural network (CNN) have semantic differences in the fusion of high- and low-layer features and ignore the potential value of speech features in channel dimension, this paper proposed a stacked multi-stage progressive gated convolutional network to achieve singing voice separation. Firstly, a gated adaptive convolution (GAC) unit was designed in each level of subnetwork to fully learn and extract the time-frequency features of songs and enhance competition and cooperation between the feature channels. Then, to reduce the semantic errors in the fusion of shallow and deep network information, a gated attention mechanism was introduced between the codec layers of the subnetwork. Finally, supervised attention (SA) was proposed for different levels of subnetwork to selectively deliver effective information flow and realize progressive learning of multi-stage networks. Comprehensive comparative experiments were carried out on a large dataset and a small dataset publicly available. The results show that compared with the representative models in recent years, the algorithm has certain advantages in separating singing voice and background accompaniment.

| [1] |
RAFII Z, PARDO B. Repeating pattern extraction technique (REPET): a simple method for music/voice separation[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2013, 21(1): 73-84. doi: 10.1109/TASL.2012.2213249
|
| [2] |
HUANG P S, CHEN S D, SMARAGDIS P, et al. Singing-voice separation from monaural recordings using robust principal component analysis[C]//Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2012: 57-60.
|
| [3] |
GRAIS E M, ERDOGAN H. Single channel speech music separation using nonnegative matrix factorization with sliding windows and spectral masks[C]//Proceedings of the Interspeech 2011. Copenhagen: ISCA, 2011: 1773-1776.
|
| [4] |
UHLICH S, GIRON F, MITSUFUJI Y. Deep neural network based instrument extraction from music[C]//Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2015: 2135-2139.
|
| [5] |
SPRECHMANN P, BRUNA J, LECUN Y. Audio source separation with discriminative scattering networks[C]//Proceedings of the Latent Variable Analysis and Signal Separation. Berlin: Springer, 2015: 259-267.
|
| [6] |
张天骐, 熊梅, 张婷, 等. 结合区分性训练深度神经网络的歌声与伴奏分离方法[J]. 声学学报, 2019, 44(3): 393-400.
ZHANG T Q, XIONG M, ZHANG T, et al. A separation method of singing and accompaniment combining discriminative training deep neural network[J]. Acta Acustica, 2019, 44(3): 393-400(in Chinese).
|
| [7] |
CHEN J T, WANG D L. Long short-term memory for speaker generalization in supervised speech separation[J]. The Journal of the Acoustical Society of America, 2017, 141(6): 4705. doi: 10.1121/1.4986931
|
| [8] |
张天. 单通道音乐信号中的人声伴奏分离方法研究[D]. 重庆: 重庆邮电大学, 2020: 43-57.
ZHANG T. Research on separation method of vocal accompaniment in single channel music signal[D]. Chongqing: Chongqing University of Posts and Telecommunications, 2020: 43-57(in Chinese).
|
| [9] |
JANSSON A, HUMPHREY E, MONTECCHIO N, et al. Singing voice separation with deep U-Net convolutional networks[C]//Proceedings of the 18th International Society for Music Information Retrieval Conference. [S. l. ]: DBLP, 2017: 745-751.
|
| [10] |
STOLLER D, EWERT S, DIXON S. Wave-U-Net: a multi-scale neural network for end-to-end audio source separation[EB/OL]. (2018-06-08)[2023-06-01]. http://arxiv.org/abs/1806.03185v1.
|
| [11] |
DÉFOSSEZ A, USUNIER N, BOTTOU L, et al. Demucs: deep extractor for music sources with extra unlabeled data remixed[EB/OL]. (2019-09-03)[2023-06-01]. http://arxiv.org/abs/1909.01174v1.
|
| [12] |
IBTEHAZ N, RAHMAN M S. MultiResUNet: rethinking the U-Net architecture for multimodal biomedical image segmentation[J]. Neural Networks, 2020, 121: 74-87. doi: 10.1016/j.neunet.2019.08.025
|
| [13] |
PARK S, KIM T, LEE K, et al. Music source separation using stacked hourglass networks[EB/OL]. (2018-06-22)[2023-06-01]. http://arxiv.org/abs/1805.08559v2.
|
| [14] |
YUAN W T, WANG S B, LI X R, et al. A skip attention mechanism for monaural singing voice separation[J]. IEEE Signal Processing Letters, 2019, 26(10): 1481-1485. doi: 10.1109/LSP.2019.2935867
|
| [15] |
BHATTARAI B, PANDEYA Y R, LEE J. Parallel stacked hourglass network for music source separation[J]. IEEE Access, 2020, 8: 206016-206027. doi: 10.1109/ACCESS.2020.3037773
|
| [16] |
买峰. 基于深度卷积神经网络的音乐源分离算法及其应用研究[D]. 成都: 电子科技大学, 2021: 20-70.
MAI F. Research on music source separation algorithm based on deep convolution neural network and its application[D]. Chengdu: University of Electronic Science and Technology of China, 2021: 20-70(in Chinese).
|
| [17] |
SUBAKAN C, RAVANELLI M, CORNELL S, et al. Attention is all you need in speech separation[C]//Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2021: 21-25.
|
| [18] |
YANG Z X, ZHU L C, WU Y, et al. Gated channel transformation for visual recognition[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 11791-11800.
|
| [19] |
YANG Y H. Low-rank representation of both singing voice and music accompaniment via learned dictionaries[C]//Proceedings of the 14th International Society for Music Information Retrieval Conference. Curitiba: [s. n. ], 2013: 427-432.
|
| [20] |
HUANG P S, KIM M, HASEGAWA-JOHNSON M, et al. Joint optimization of masks and deep recurrent neural networks for monaural source separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(12): 2136-2147. doi: 10.1109/TASLP.2015.2468583
|
| [21] |
SEBASTIAN J, MURTHY H A. Group delay based music source separation using deep recurrent neural networks[C]//Proceedings of the International Conference on Signal Processing and Communications. Piscataway: IEEE Press, 2016: 1-5.
|
| [22] |
DÉFOSSEZ A, USUNIER N, BOTTOU L, et al. Music source separation in the waveform domain[EB/OL]. (2021-04-28)[2023-06-01]. http://arxiv.org/abs/1911.13254v2.
|
| [23] |
YUAN W T, DONG B F, WANG S B, et al. Evolving multi-resolution pooling CNN for monaural singing voice separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 807-822. doi: 10.1109/TASLP.2021.3051331
|
| [24] |
TAKAHASHI N, MITSUFUJI Y, TAKAHASHI N, et al. D3Net: densely connected multidilated DenseNet for music source separation[EB/OL]. (2021-05-27)[2023-06-01]. http://arxiv.org/abs/2010.01733v4.
|
| [25] |
LAI W H, WANG S L. RPCA-DRNN technique for monaural singing voice separation[J]. EURASIP Journal on Audio, Speech, and Music Processing, 2022, 2022: 4. doi: 10.1186/s13636-022-00236-9
|
| [26] |
NI X, REN J. FC-U2-Net: a novel deep neural network for singing voice separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022, 30: 489-494. doi: 10.1109/TASLP.2022.3140561
|
Figures(7) / Tables(6)
Copyright © Journal of Beijing University of Aeronautics and Astronautics
Address: Editorial Department of Journal of Beijing University of Aeronautics and Astronautics, 37 Xueyuan Road, Haidian District, Beijing Post Code: 100191 Email: jbuaa@cqjj8.com
Supported by:
Beijing Renhe Information Technology Co., Ltd.





 DownLoad:
DownLoad: